Entstehungszeit: 2.Nov 2023 – 6.Jan 2023
Autor: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
KONTEXT
Der folgende Text ist die nachträgliche Verschriftlichung einer Vorlesung, die der Autor für die Internet-Arbeitsgruppe ENIGMA [3] der U3L [1,2] der Goethe-Universität Frankfurt am 10.November 2023 gehalten hat. Er stellt eine Weiterentwicklung eines Konferenzbeitrags dar, der bei de Gruyter veröffentlicht wurde: Kollektive Mensch-Maschine-Intelligenz und Text-Generierung. Eine transdisziplinäre Analyse (2023). Man kann auch alle anderen Beiträge (open access) herunterladen.
Der Ankündigungstext lautet:
Kollektive Mensch-Maschine Intelligenz im Kontext
nachhaltiger Entwicklung – Brauchen wir ein neues
Menschenbild?
Prof. Dr. Gerd Doeben-Henisch, Frankfurt University
of Applied Sciences
Die Zeichen der Zeit stehen auf ‚Digitalisierung‘. Schon ist es selbstver-
ständlich, alles, was ‚digital‘ ist, auch mit den Worten ‚smart‘ bzw.‚
intelligent‘ zu verknüpfen. ‚Künstliche Intelligenz‘, ja, natürlich, wer fragt
da noch nach … und wir Menschen, war da nicht was? Gab es nicht
solche Worte wie ‚Geist‘, ‚Rationalität‘, ‚Intelligenz‘ im Umfeld des
Menschen, ‚Wille‘ und ‚Gefühle‘? Ja, es gab eine Zeit, da sahen die
Menschen sich selbst als ‚Krone der Schöpfung‘ … Und jetzt? Eine
Sprachlosigkeit greift um sich; der ‚Schöpfer‘ des Digitalen scheint vor
seinem Werk zu erstarren …
[1] Home u3l: https://www.uni-frankfurt.de/122411224/U3L_Home?
[2] Vorlesungsverzeichnis u3l-WS2023: https://www.uni-frankfurt.de/141923421/programm-ws-2023-24.pdf
[3] Flyer der Vorlesungsreihe WS23/24: https://www.uni-frankfurt.de/144405162.pdf
Zusammenfassung
Die Vorlesung greift zunächst den Kontext der Digitalisierung auf und macht die grundlegenden Strukturen deutlich. Das Eindringen von digitalen Technologien und deren Nutzung im Alltag ist schon jetzt sehr tiefgreifend. Gesellschaftlich spielt die sprachliche Kommunikation für alle Menschen und alle Abläufe eine zentrale Rolle. Literarischen und wissenschaftlichen Kommunikationsformaten kommt hierbei eine besondere Rolle zu. Am Beispiel der neuen Algorithmen für Text-Generierung (wie z.B. chatGPT) wird mit Bezug auf wissenschaftliche Kommunikationformate gezeigt, wie deutlich begrenzt die algorithmische Text-Generierung noch ist. Für alle drängenden Zukunftsaufgaben kann sie den Menschen aufgrund prinzipieller Grenzen nicht ersetzen. Die weitere Ausgestaltung algorithmischer Technologien muss an diesen gesellschaftlichen Herausforderungen gemessen und entsprechend verbessert werden.
INHALTSVERZEICHNIS
- EINLEITUNG
- DIGITALISIERUNG
2.1 DAS INTERNET
2.2 DIE GESELLSCHAFT - DIGITALISIERUNG – SPRACHTECHNOLOGIEN
- GESELLSCHAFT – SPRACHE – LITERATUR
- SPRACHE UND BEDEUTUNG
- ZÄHMUNG DER BEDEUTUNG – WISSENSCHAFT
- EMPIRISCHE THEORIE
- WAHRHEIT, PROGNOSE & TEXT-GENERATOREN
- Epilog
1. EINLEITUNG
Der Titel dieser Vorlesung repräsentiert letztlich das Forschungsparadigma, innerhalb dessen sich der Autor seit ca. 5-6 Jahren bewegt hat. Das Motiv war — und ist –, die üblicherweise isolierten Themen ‚Kollektives menschliches Verhalten‘, ‚Künstliche Intelligenz‘ sowie ‚Nachhaltige Entwicklung‘ zu einer kohärenten Formel zu vereinigen. Dass dies nicht ohne Folgen für das ‚Menschenbild‘ bleiben würde, so wie wir Menschen uns selbst sehen, klang unausgesprochen immer schon zwischen den Zeilen mit.
Die Integration der beiden Themen ‚kollektives menschliches Verhalten‘ sowie ’nachhaltige Entwicklung‘ konnte der Autor schon im Jahr 2022 vollziehen. Dazu musste der Begriff ‚Nachhaltige Entwicklung‘ re-analysiert werden. Was sowohl im Umfeld des Forschungsprojektes Nachhaltige Intelligenz – intelligente Nachhaltigkeit [1] stattfand wie auch in einer sich über 7 Semester erstreckende multidisziplinären Lehrveranstaltung an der Frankfurt University of Applied Sciences mit dem Titel Citizen Science für Nachhaltige Entwicklung.[2]
Die Integration des Themas Künstliche Intelligenz mit den beiden anderen Themen erwies sich als schwieriger. Dies nicht, weil das Thema künstliche Intelligenz so schwer war, sondern weil sich eine brauchbare Charakterisierung von künstlicher Intelligenz Technologie mit Blick auf die Bedürfnisse einer Gesellschaft als schwer erwies: bezogen auf welche Anforderungen einer Gesellschaft sollte man den Beitrag einer künstlichen Intelligenz gewichten?
Hier kamen zwei Ereignisse zu Hilfe: Im November 2022 stellte die US-Firma openAI eine neue Generation von Text-Generatoren vor [3], was zu einer bis dahin nie gekannten Publikations-Explosion führte: Gefühlt jeder fühlte sich angesprochen, nutzte das Werkzeug, und es gab vielstimmige Meinungsäußerung. In folge davon konnte der Autor sich bei einer Konferenz an der TU-Darmstadt beteiligen mit dem Titel Diskurse disruptiver digitaler Technologien am Beispiel von KI-Textgeneratoren (KI:Text) [4]. Hier wurde aus Sicht von 18 Perspektiven versucht, die mögliche Einsetzbarkeit von Text-Generatoren am Beispiel konkreter Text-Arten zu untersuchen. Diese Konferenz stimulierte den Plan, das Setting Text – chatGPT zu übernehmen und es durch Spezialisierung der Text-Variablen auf Literatur und insbesondere wissenschaftliche Theorien zu konkretisieren. Erste Überlegungen in diese Richtungen finden sich hier. [5]
Im Nachklang zu diesen Überlegungen bot es sich an, diese Gedanken im Vortrag für die Arbeitsgruppe ENIGMA weiter zu präzisieren. Dies ist geschehen und resultierte in diesem Vortrag.
[1] https://zevedi.de/themen/nachhaltige-intelligenz-intelligente-nachhaltigkeit/
[2] Materialien zur 6. und 7.Auflage: https://www.oksimo.org/lehre-2/
[3] Kurze Beschreibung: https://en.wikipedia.org/wiki/ChatGPT
[4] https://zevedi.de/themen/ki-text/
[5] Gerd Doeben-Henisch, 24.Aug 2023, Homo Sapiens: empirische und nachhaltig-empirische Theorien, Emotionen, und Maschinen. Eine Skizze, https://www.cognitiveagent.org/2023/08/24/homo-sapiens-empirische-und-nachhaltig-empirische-theorien-emotionen-und-maschinen-eine-skizze/
2. DIGITALISIERUNG
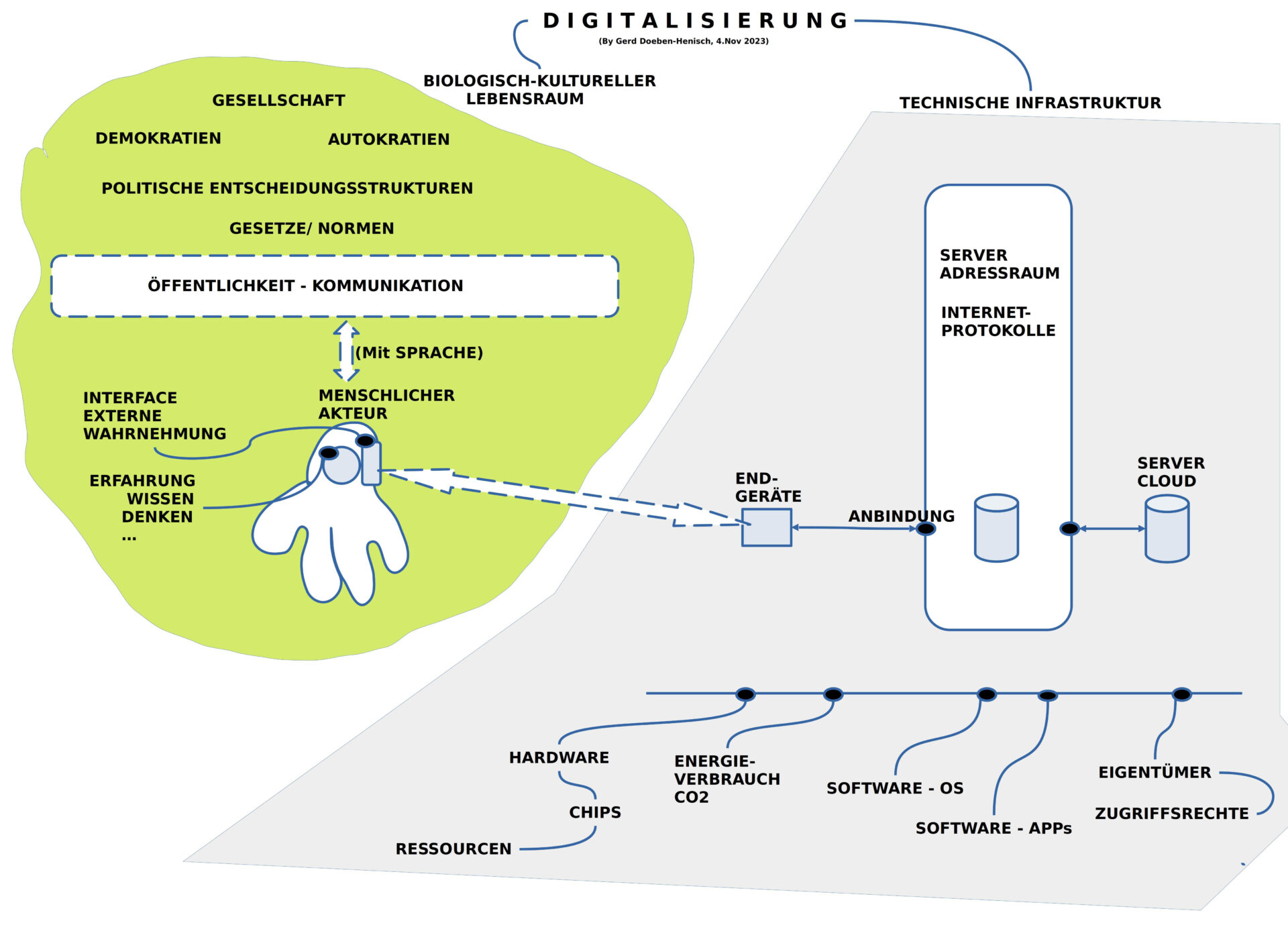
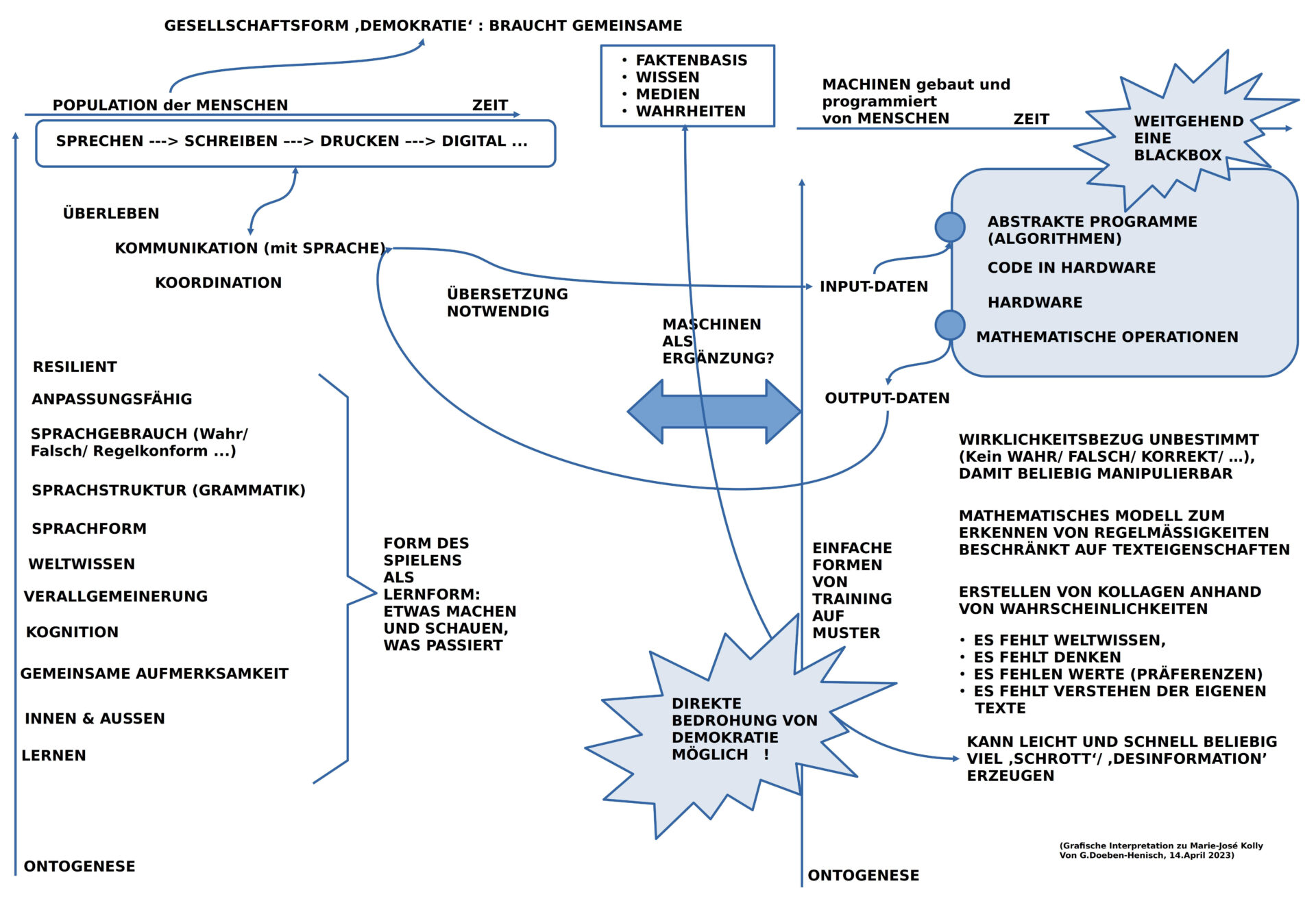
BILD 1: Überblick zu ‚Digitalisierung einer Gesellschaft‘
Da die ‚Digitalisierung‘ heute gefühlt schon fast alle Bereiche unserer menschlichen Gesellschaft erreicht hat, ist es nicht leicht in dieser Vielfalt einen Standpunkt zu lokalisieren, von dem aus sich sowohl über das Ganze wie auch über einzelne konkrete Themen zu sprechen. [1]
Es bot sich daher an, mit einem vereinfachten Überblick über das Ganze zu starten, so dass eine für alle gleiche Ausgangslage hergestellt werden konnte.
Im Bild 1 kann man den links gelblich-grünen Bereich sehen, der für die Gesellschaft selbst steht, und einen grauen Bereich rechts, der für jene Infrastrukturen steht, die eine Digitalisierung technisch ermöglichen. Beide Bereich sind stark schematisiert.
Die digitale Infrastruktur ist aufgeteilt in ‚Endgeräte‘ und in das eigentliche ‚Internet‘. Letzteres wird unterschieden in den ‚Adressraum‘ und jene Geräte, die über den Adressraum erreicht werden können.
2.1 DAS INTERNET
Kurz wurde auf einige wichtige Eigenschaften des Internets hingewiesen:
- Alle beteiligten Geräte setzen sich aus ‚Hardware‘ und ‚Software‘ zusammen. Die Hardware wiederum besteht aus einer Konfiguration von ‚Chips‘, die selbst sehr komplex sind und auch aus Hardware und Software bestehen. Bis zu ca. 80 Firmen können bei der Produktion eines einzelnen Chips beteiligt sein (unter Berücksichtigung der diversen Lieferketten). Die Möglichkeit, dass eine beteiligte Firma ’nicht-intendierte‘ Funktionen in einen Chip einbaut, ohne dass die anderen dies merken, sind prinzipiell gegeben. Die für Chips benötigten speziellen Materialien sind partiell ’selten‘ und nur über einige wenige Staaten beziehbar.
- Die ‚Software‘ auf einem Rechner (klein bis groß) zerfällt grob in zwei Typen: (i) jene Software, die die grundlegende Kommunikation mit einer Hardware ermöglicht — das ‚Betriebssystem‘ –, und jene Software, die bestimmte Anwendungen ermöglicht, die mit dem Betriebssystem kommunizieren muss — die Anwendungssoftware, heute auch einfach App genannt –. Betriebssysteme haben heute eine Größe, die vielen Millionen Zeilen Code umfassen. Eine solche Software angemessen auf Dauer zu managen, stellt extreme Anforderungen. Nicht weniger im Fall von Anwendungssoftware.
- Sobald Software aktiviert wird, d.h. ein Rechner ändert seine inneren Zustände unter dem Einfluss der Software, wird Energie verbraucht. Der Umfang dieses Energieverbrauchs ist heute noch vielfach extrem hoch.[2]
- Ein ‚realer Rechner‘ braucht irgendwo auf diesem Planeten einen ‚realen Ort‘ und gehört eine ‚realen Besitzer‘. Dieser Eigentümer hat prinzipiell den vollen Zugriff auf den Rechner, auf seine Software, auf seine Inhalte. Durch die ‚Gesetze‘ eines Landes, durch ‚Vereinbarungen‘ zwischen Geschäftspartnern kann man den Umgang mit dem Rechner versuchen zu regeln, aber Garantien dafür, dass dann tatsächlich die Prozesse und die Daten ‚geschützt‘ sind, gibt es nicht. Eine von vielen Untersuchungen zur Nutzung von Benutzerdaten konnte am Beispiel von Facebook aufzeigen, dass die Einführung der europäischen Datenschutzverordnung 2021 nahezu keine Wirkung im Bereich der Nutzerdaten von Facebook zeigte. [3,4,5]
[1] Phänomen: Den Wald vor lauter Bäume nicht sehen.
[2] Maximilian Sachse, Das Internet steht unter Strom. KI kann helfen, Emissionen einzusparen — verbraucht aber selbst Unmengen an Energie.FAZ, 31.Okt 2023, S.B3
[3] José González Cabañas, Ángel Cuevas, Aritz Arrate, and Rubén Cuevas. 2020. Does Facebook use sensitive data for advertising purposes? Commun. ACM 64, 1 (January 2021), 62–69. https://doi.org/10.1145/3426361
[4] Eine ausführlichere Analyse der Informationsbeschaffung von Nutzern ohne deren Wissen: Ingo Dachwitz, 08.06.2023, Wie deutsche Firmen am Geschäft mit unseren Daten verdienen. Wenn es um Firmen geht, die pausenlos Daten für Werbezwecke sammeln, denken viele an die USA. Unsere Recherche zeigt, wie tief deutsche Unternehmen inzwischen in das Netzwerk der Datenhändler verwoben sind und dass sie auch heikle Datenkategorien anboten. Beteiligt sind Konzerne wie die Deutsche Telekom und ProSieben Sat1, URL: https://netzpolitik.org/2023/adsquare_theadex_emetriq_werbetracking-wie-deutsche-firmen-am-geschaeft-mit-unseren-daten-verdienen/
[5] Ein aktuelles Beispiel mit Microsoft: Dirk Knop, Ronald Eikenberg, Stefan Wischner, 09.11.2023, Microsoft krallt sich Zugangsdaten: Achtung vor dem neuen Outlook. Das neue kostenlose Outlook ersetzt Mail in Windows, später auch das klassische Outlook. Es schickt geheime Zugangsdaten an Microsoft. c’t Magazin, Heise
2.2 DIE GESELLSCHAFT
Die Charakterisierung der Gesellschaft stellt natürlich auch eine starke Vereinfachung dar. Als wichtige Strukturmerkmale seien hier aber festgehalten:
- Es gibt eine Grundverfassung jeder Gesellschaft jenseits von Anarchie die zwischen den beiden Polen ‚Demokratisch‘ und ‚Autokratisch‘ liegt.
- Es gibt minimal ‚politische Entscheidungsstrukturen‘, die verantwortlich sind für geltende ‚Gesetze‘ und ‚Normen‘.
- Die Schlagader jeder lebendigen Gesellschaft ist aber die ‚Öffentlichkeit durch Kommunikation‘: wenn, dann verbindet Kommunikation die vielen Bürger zu handlungsfähigen Einheiten. Autokratien tendieren dazu, Kommunikation zu ‚instrumentalisieren‘, um die Bürger zu manipulieren. In Demokratien sollte dies nicht der Fall sein. Tatsächlich kann aber die Freiheit einer Demokratie von partikulären Interessen missbraucht werden.[1]
- Jeder einzelne Bürger ist als ‚menschlicher Akteur‘ eingewoben in unterschiedliche Kommunikationsbeziehungen, die vielfach durch Einsatz von ‚Medien‘ ermöglicht werden.
[1] Sehr viele interessante Ideen zur Rolle de Öffentlichkeit finden sich in dem Buch Strukturwandel der Öffentlichkeit von Jürgen Habermas, veröffentlicht 1962. Siehe dazu ausführlich den Wikipedia-Eintrag: https://de.wikipedia.org/wiki/Strukturwandel_der_%C3%96ffentlichkeit
[2] Florian Grotz, Wolfgang Schroeder, Anker der Demokratie? Der öffentlich-rechtliche Rundfunk hat einen wesentlichen Beitrag zum Erfolg der deutschen Demokratie geleistet. Derzeit steht er im Kreuzfeuer der Kritik. Wie kann er auch künftig seine Ankerfunktion im demokratischen Mediensystem erfüllen? FAZ 13.Nov 2023, S.6, Siehe auch online (beschränkt): https://www.faz.net/aktuell/politik/die-gegenwart/ard-und-zdf-noch-im-dienst-der-demokratie-19309054.html Anmerkung: Die Autoren beschreiben kenntnisreich die historische Entwicklung des öffentlich-rechtlichen Rundfunks (ÖRR) in drei Phasen. Verschiedene Schwierigkeiten und Herausforderungen heute werden hervor gehoben. Der generelle Tenor in allem ist, dass von ’notwendigen Veränderungen‘ gesprochen wird. Diese werden über die Themen ‚Finanzierung, Programm und Kontrolle‘ ein wenig ausgeführt. Dies sind alles sehr pragmatische Aspekte. Wenn es dann im Schlusssatz heißt „Es geht darum, dass der ÖRR auch in Zukunft eine wichtige Rolle im Dienst der Demokratie spielen kann.“ dann kann man sich als Leser schon fragen, warum ist der ÖRR denn für die Demokratie so wichtig? Finanzen, Programme und Kontrolle sind mögliche pragmatische Teilaspekte, aber eine eigentliche Argumentation ist nicht zu erkennen. Mit Blick auf die Gegenwart, in welcher die ‚Öffentlichkeit‘ in eine Vielzahl von ‚Medienräumen‘ zerfällt, die von unterschiedlichen ‚Narrativen‘ beherrscht werden, die sich gegenseitig auszuschließen scheinen und die ein von einer echten Mehrheit getragenes politisches Handeln unmöglich erscheinen lassen, sind Finanzen, Kontrollen, formale Programmvielfalt nicht unbedingt wichtige konstruktive Kriterien. Der zusätzlich verheerende Einfluss neuer bedeutungsfreier Texte-generierende Technologien wird mit den genannten pragmatischen Kriterien nicht einmal ansatzweise erfasst.
3. DIGITALISIERUNG – SPRACHTECHNOLOGIEN
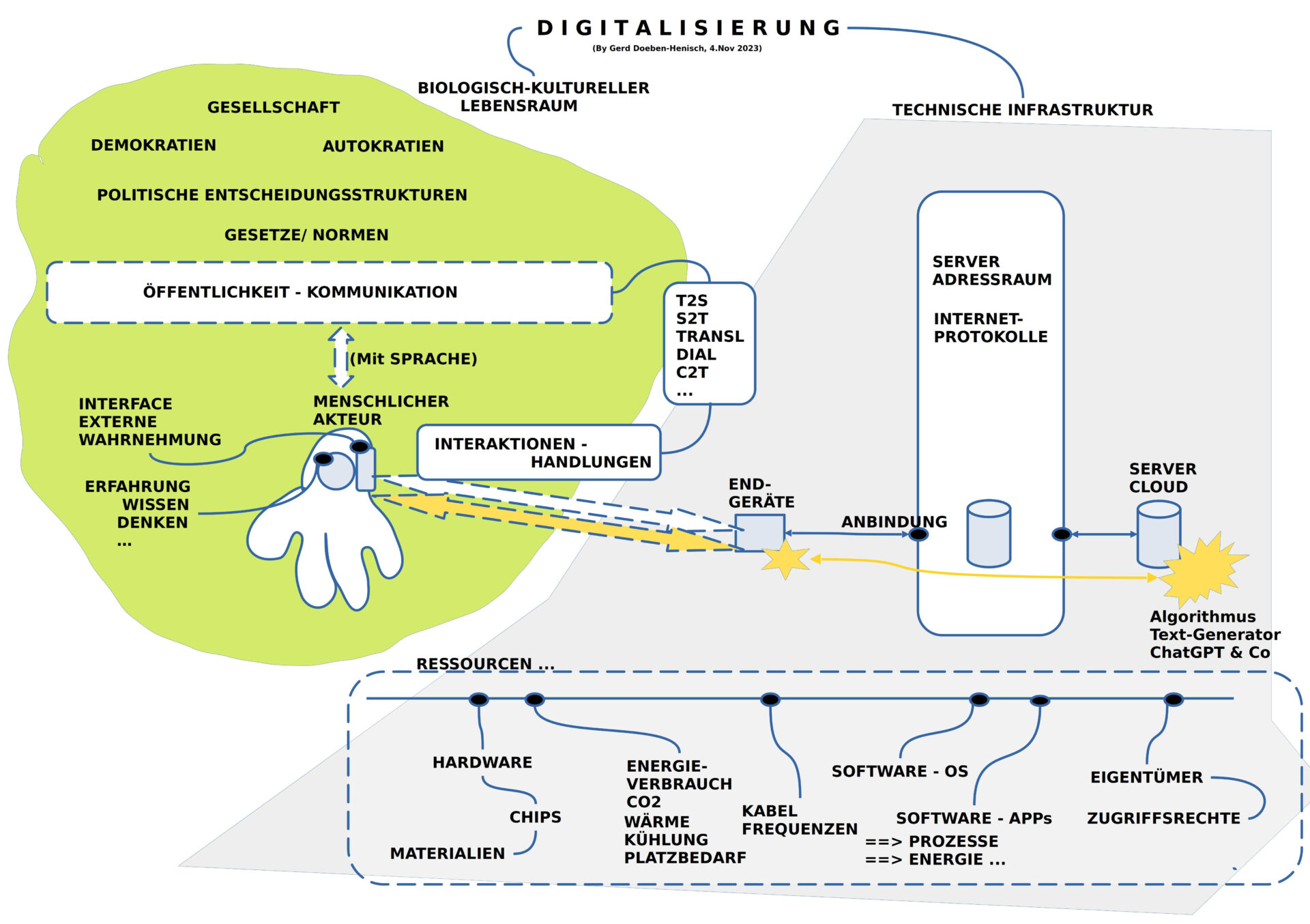
BILD 2 : Das Enstehen von Sprachtechnologien zur Unterstützung im Umgang mit Sprache
Dem ‚Weltereignis‘ Text-Generatoren im November 2022 gingen viele andere Sprachtechnologien voraus. So unterscheidet man grob:
- TTS, T2S , Text-to-Speech, Speechsynthesis: Erste Systeme, die geschriebenen Text in gesprochene Sprache umsetzen konnten. Ab 1968 [1]
- S2T, STT , Speech-to-Text: Spracherkennungssysteme, die gesprochene Sprache in geschriebenen Text verwandelt konnten. Ab 1952 [2]
- TRANSL , Maschineller Übersetzer: Programme, die von einer Ausgangssprache in eine Zielsprache übersetzen können. Ab 1975. [3]
- DIAL , Dialogsysteme: Programme, die mit Menschen Dialoge führen können, um bestimmte Aufgaben zu unterstützen. Ab 1960iger Jahre. [4]
- C2T , Command-to-Text: Programme, die anhand von Aufforderungen Texte mit bestimmten Eigenschaften generieren können. Prominent ab November 2022. [5]
Mittlerweile gibt es noch eine Vielzahl anderer Werkzeuge, die im Rahmen der Computerlinguistik zur Arbeit mit Texten angeboten werden.[6]
Diese Beispiele zeigen, dass die Digitalisierung unserer Welt sich auch immer mehr unserer sprachlichen Kommunikation bemächtigt. Vielfach werden diese Werkzeuge als Hilfe, als Unterstützung wahrgenommen, um die menschliche Sprachproduktion besser verstehen und im Vollzug besser unterstützen zu können.
Im Fall der neuen befehlsorientierten Text-Generatoren, die aufgrund interner Datenbanken komplexe Texte generieren können, die für einen Leser ‚wie normale Texte von Menschen‘ daher kommen, wird der Raum der sprachlichen Kommunikation erstmalig von ’nicht-menschlichen‘ Akteuren durchdrungen, die eine stillschweigende Voraussetzung außer Kraft setzen, die bislang immer galt: es gibt plötzlich Autoren, die keine Menschen mehr sind. Dies führt zunehmend zu ernsthaften Irritationen im sprachlichen Diskursraum. Menschliche Autoren geraten in eine ernsthafte Krise: sind wir noch wichtig? Werden wir noch gebraucht? Ist ‚Menschsein‘ mit einem Schlag ‚entwertet‘?
[1] Erste Einführung hier: https://en.wikipedia.org/wiki/Speech_synthesis
[2] Erste Einführung hier: https://en.wikipedia.org/wiki/Speech_recognition
[3] Erste Einführung hier: https://en.wikipedia.org/wiki/Machine_translation
[4] Erste Einführung hier: https://en.wikipedia.org/wiki/Dialogue_system
[5] Erste Einführung hier: https://en.wikipedia.org/wiki/ChatGPT
[6] Für eine erste Einführung siehe hier: https://de.wikipedia.org/wiki/Computerlinguistik
4. GESELLSCHAFT – SPRACHE – LITERATUR
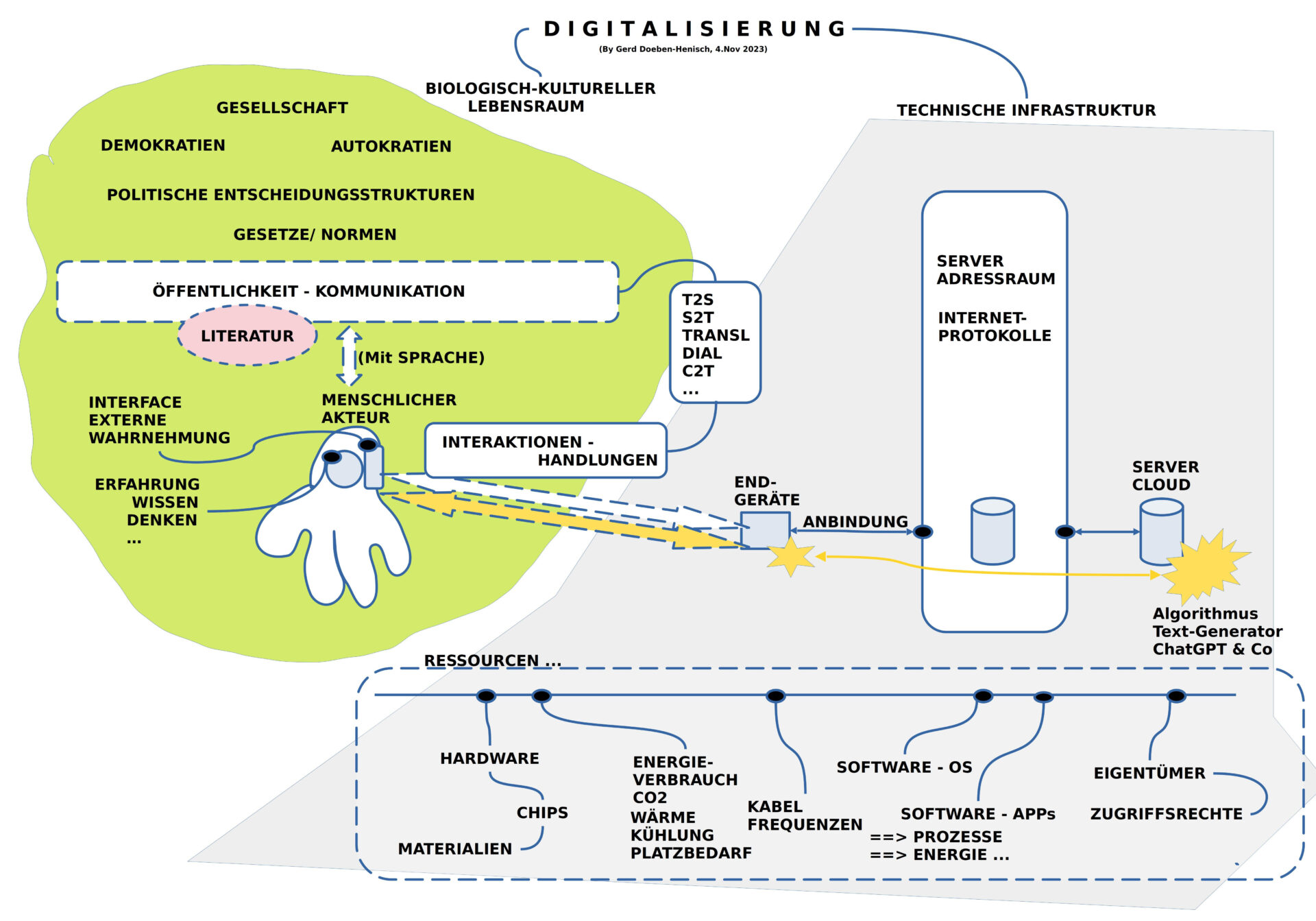
BILD 3 : Sprachtechnologien und Literatur
Das Auftreten der neuen Werkzeuge zur Text-Generierung stiftet eine anhaltende Unruhe im Lager der Schriftsteller, der Autoren und der Literaturwissenschaftler.
Ein beeindruckendes Beispiel ist die Analyse von Hannes Bajohr (2022).[1] Er spielt die Varianten durch, was passiert, wenn … Was passiert, wenn sich die Produktion von literarischen Texten mit Text-Generatoren durchsetzt? Wenn es zum Standard wird, dass immer mehr Texte, ganze Romane mit Text-Generatoren erzeugt werden? Und dies sind keine bloßen Träume, sondern solche Texte werden schon produziert; Bajohr selbst hat einen Roman unter Zuhilfenahme eines Text-Generators verfasst.[2]
Eine andere junge Autorin und Kulturwissenschaftlerin, die sich intensiv mit dem neuen Wechselverhältnis von Literatur, digitaler Welt und Text-Generatoren auseinander setzt ist Jenifer Becker.[3] Ihr Debüt-Roman ist aber noch ein Roman ohne Einsatz von künstlichen Texterzeugern. In ihrem Roman spricht sie noch ’selbst‘ als ‚menschliche Autorin‘ und wir damit potentiell zu einer Gesprächspartnerin für ihre Leser: der Andere als potentielles Ich, wobei das ‚eigentliche Ich‘ sich Spiegel des Textes in spannungsvoller Differenz erleben kann.
Angesichts einer digitalisierten Welt, die mehr und mehr zu einer ‚Ereigniswelt‘ wird, in der das ‚Verweilen‘, das ‚Verstehen‘ sich immer mehr abschwächt, verstummt, verliert auch das Individuum seine eigene Kraft und beginnt sich ‚hohl‘ anzufühlen, wo es doch gar nicht hohl ist, nicht hohl sein muss.
Hier setzt die Rede zur Nobelpreisverleihung 2018 für Literatur der polnischen Laureatin Olga Tokarczuk ein. Sie beschreibt als das Wunderbare von Literatur gerade diese einzigartige Fähigkeit von uns Menschen, dass wir mittels Sprache von unserem Innern berichten können, von unserer individuellen Art des Erlebens von Welt, von Zusammenhängen, die wir in dem Vielerlei des Alltags entdecken können, von Prozessen, Gefühlen, von Sinn und Unsinn. [4]
In dieser Eigenschaft ist Literatur durch nichts ersetzbar, bildet Literatur den ‚inneren Herzschlag‘ des Menschlichen auf diesem Planeten.
Aber, und dies sollte uns aufhorchen lassen, dieser wunderbarer Schatz von literarischen Texten wird bedroht durch den Virus der vollständigen Nivellierung, ja geradezu eine vollständigen Auslöschung. Text-Generatoren haben zwar keinerlei Wahrheit, keinerlei realen Bindungen an eine reale Welt, an reale Menschen, keinerlei wirkliche Bedeutung, aber in der Produktion von Texten (und gesprochener Rede) ohne Wahrheit sind sie vollständig frei. Durch ihre hohe Geschwindigkeit der Produktion können sie alle ‚menschliche Literatur‘ in der Masse des Bedeutungslosen aufsaugen, unsichtbar machen, nihilieren.
[1] Hannes Bajohr, 2022, Artifizielle und postartifizielle Texte. Über Literatur und Künstliche Intelligenz. Walter-Höllerer-Vorlesung 2022, 8.Dez. 2022, Technische Universität Berlin , URL: https://hannesbajohr.de/wp-content/uploads/2022/12/Hoellerer-Vorlesung-2022.pdf, Den Hinweis auf diesen Artikel erhielt ich von Jennifer Becker.
[2] Siehe dazu Bajohr selbst: https://hannesbajohr.de/
[3] Jenifer Becker, Zeiten der Langeweile, Hanser, Berlin, 2023. Dazu Besprechung in der Frankfurter Rundschau, 30.8.23, Lisa Berins, Die große Offline-Lüge, https://www.fr.de/kultur/literatur/zeiten-der-langeweile-von-jenifer-beckerdie-grosse-offline-luege-92490183.html
[4] Olga Tokarczuk, 2018, The Tender Narrator, in: Nobel Lecture by Olga Tokarczuk, 2018, Svenska Akademien, URL: https://www.nobelprize.org/uploads/2019/12/tokarczuk-lecture-english-2.pdf
5. SPRACHE UND BEDEUTUNG
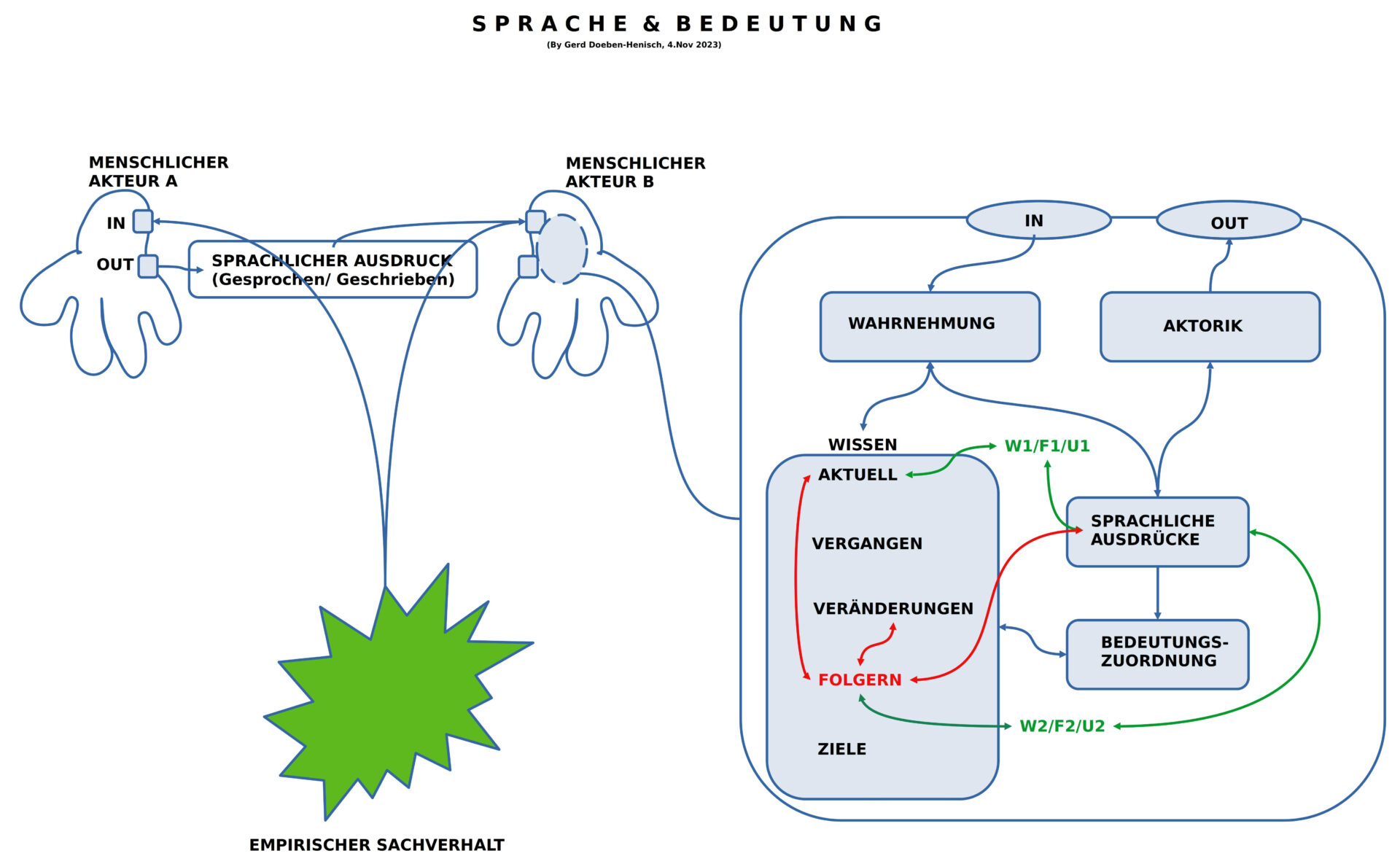
BILD 4 : Sprache und Bedeutung
Am Beispiel der ‚menschlichen Literatur‘ klang eben schon an, welch fundamentale Rolle die ‚Bedeutung von Sprache‘ spielt und dass wir Menschen über solch eine Fähigkeit verfügen. Im Schaubild 4 wird veranschaulicht, was es bedeutet, dass Menschen im Alltag scheinbar mühelos Aussagen erzeugen können, die als ‚aktuell zutreffend’/ ‚wahr‘ untereinander akzeptiert werden oder als ‚aktuell nicht zutreffend’/ ‚falsch‘ oder als ‚aktuell unbestimmt‘. Wenn ein konkreter empirischer Sachverhalt gegeben ist (der Hund von Ani, das rote Auto vom Nachbarn Müller, die Butter auf dem Frühstückstisch, …), dann ist eine Einigung zwischen Menschen mit der gleichen Sprache immer möglich.
Was man sich dabei selten bewusst macht ist, welch starke Voraussetzung ‚in einem Menschen‘ gegeben sein müssen, damit er über diese Fähigkeit so leicht verfügen kann.
Die ‚Box‘ im rechten Teil des Diagramms repräsentiert auf einem starken Abstraktionsniveau die wichtigsten Komponenten, über die ein Mensch in seinen inneren Verarbeitungsstrukturen verfügen können muss, damit er mit anderen so sprechen kann. Die Grundannahmen sind folgende:
- Eine Außenwahrnehmung der umgebenden (empirischen) Welt.
- Alles was wahrgenommen werden kann kann auch in ‚Elemente des Wissens‘ verwandelt werden.
- Eine Sonderrolle nimmt die Repräsentation von Elementen der Sprachstruktur ein.
- Zwischen den Elementen des Wissens und den Ausdruckselementen kann ein Mensch eine dynamische Abbildungsbeziehung (Bedeutungsbeziehung) aufbauen (Lernen), so dass Wissenselemente auf Ausdruckselemente verweisen und Ausdruckselemente auf Wissenselemente.
- Aus Sicht der Ausdruckselemente bildet jenes Wissen, das über eine Abbildung verbunden wird, die ‚Bedeutung‘ der Ausdruckselemente.
- Innerhalb des Wissens gibt es zahlreiche unterschiedliche Formen von Wissen: aktuelles Wissen, erinnerbares Wissen, Veränderungswissen, Ziele, und prognostisches Wissen.
- Und vieles mehr
Neben Aussagen, die ‚aktuell wahr‘ sein können, verfügt der Mensch aber auch über die Möglichkeit, vielfache Wiederholungen als ‚wahr‘ anzusehen, wenn sie sich immer wider als ‚aktuell wahr‘ erweisen. Dies verweist auf mögliche weitere Formen von möglichen abgeleiteten Wahrheiten, die man vielleicht unter dem Oberbegriff ’strukturelle Wahrheit‘ versammeln könnte.
6. ZÄHMUNG DER BEDEUTUNG – WISSENSCHAFT
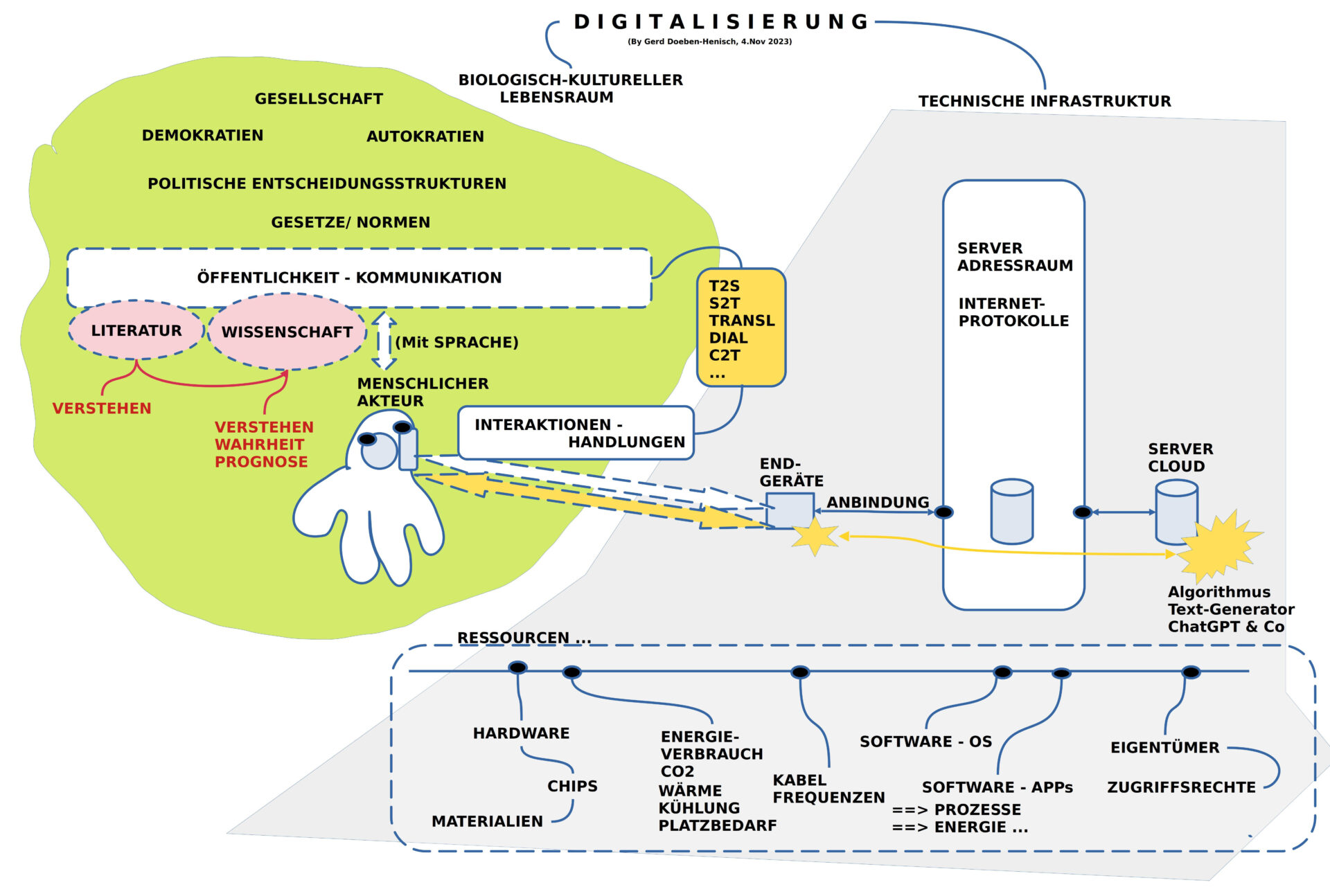
BILD 5 : Wissenschaft als Ergänzung von Literatur
Die Ur-Funktion von Literatur, das Gespräch zwischen dem Inneren der Menschen über ihre Welt- und Selbsterfahrung sprechen zu können, indem nicht nur die ‚Oberfläche der Dinge‘, sondern auch die ‚Tiefenstruktur der Phänomene‘ ins Wort kommen können, ist unersetzbar, aber sie leidet im Alltag an der strukturellen Schwäche des möglichen ‚Nicht-Verstehens‘ oder ‚Falsch-Verstehens‘. Während sich über die Dinge des alltäglichen Lebens leicht Einigkeit erzielen lässt, was jeweils gemeint ist, ist das ‚Innere‘ des Menschen eine echte ‚Terra Incognita‘, ein ‚unbekanntes Land‘. In dem Maße, wie wir Menschen im Innern ‚ähnlich‘ erleben und empfinden, kann das Verstehen von ‚Bedeutungen‘ noch ansatzweise gelingen, da wir Menschen aufgrund unserer Körperstrukturen in vielen Dingen ähnliche Erleben, Fühlen, Erinnern und Denken. Aber je spezifischer etwas in unserem Inneren ist, je ‚abstrakter‘ eine Bedeutung wird, umso schwieriger wird die Erfassung einer Rede durch andere. Dies führt dann unabwendbar zum Falsch- oder gar Nicht-Verstehen.
In dem Maße wie wir Menschen aber auf eine ‚tragfähige Erklärung von Welt‘ angewiesen sind, um ‚gemeinsam‘ das ‚Richtige‘ zu tun, in dem Maße wird unsere normale sprachliche Kommunikation, wird Literatur überfordert. Sie will vielleicht, aber sie kann aus sich heraus eine solche Eindeutigkeit nicht ohne weiteres herstellen. Ihre Stärke kann und wird in diesen Bereich zu einer Schwäche.
Vor dem Hintergrund des ‚Überlebens auf dem Planeten‘, des ‚Überlebens im Alltag‘ bildet die Notwendigkeit von ‚wahren Texten‘, die zudem ‚belastbare Prognosen‘ erlauben, eine Kernforderung, die möglicherweise nur eine Teilmenge jener Bedeutungsräume erlaubt, über die Literatur verfügen kann. Aber diese ‚wahren und belastbaren Teilräume‘ bilden jenen ‚harten Boden‘, auf denen sich Menschen quer über alle Kontinente und im Bereich aller Sprachen gründen können.
Diese Art von Texten, deren Existenz von gemeinsamen nachprüfbaren ‚wahren Sachverhalten und Prognosen‘ abhängt, entstand in der Geschichte der Menschheit unter dem Namen ‚empirische Wissenschaft‘ sehr spät.[1] Nach anfänglichen Mühen entwickelte sie sich dann rasant weiter und ist heute zum Standard für nachweisbar wahre und prognosefähige Texte geworden.
Die heutige weltweite Verbreitung von ‚Wissenschaft‘ ist ihr selbst aber mittlerweile zum Problem geworden. Der klare Kern dieser Textform erscheint in der öffentlichen Verwendung der Charakterisierung von ‚Wissenschaft‘ seltsam vage. Der Begriff einer ‚empirischen Theorie‘ ist geradezu verschwunden. Die großen Enzyklopädien dieser Welt kennen diesen Begriff nicht mehr.
Dazu kommt die ‚Altlast‘ der modernen Wissenschaft, dass sie sich schnell zu einer Veranstaltung von ‚Spezialisten‘ entwickelt hat, die ihre ‚eigene Fachsprache‘ sprechen, die zudem vielfach teilweise oder ganz mit ‚mathematischer Sprache‘ arbeiten. Diese führt zunehmend zu einer Ausgrenzung aller anderen Bürger; das ‚Verstehen von Wissenschaft‘ wird für die meisten Menschen zu einer ‚Glaubenssache‘, wo doch Wissenschaft gerade angetreten war, um die ‚Autorität des bloßen Glaubens‘ zu überwinden.
Desweiteren haben wir in den letzten Jahrzehnten mehr und mehr gelernt, was es heißt, den Aspekt ‚Nachhaltiger Entwicklung‘ zu berücksichtigen. Eine Grundbotschaft besteht darin, dass alle Menschen einbezogen werden müssen, um die Entwicklung nicht von einzelnen, kleinen — meist mächtigen — Gruppen dominieren zu lassen. Und von de Entwicklung des Lebens auf diesem Planeten [3] wissen wir, dass das Leben — von dem wir als Menschen ein kleiner Teil sind — in den zurück liegenden ca. 3.5 Milliarden Jahren nur überleben konnten, weil es nicht nur das ‚Alte, Bekannte‘ einfach wiederholt hat, sondern auch immer ‚aus sich echtes Neues‘ heraus gesetzt hat, Neues, von dem man zum Zeitpunkt des Hervorbringens nicht wusste, ob es für die Zukunft brauchbar sein wird.[3,4]
Dies regt dazu an, den Begriff der ‚empirischen Theorie‘ zu aktualisieren und ihn sogar zum Begriff einer ’nachhaltigen empirischen Theorie‘ zu erweitern.
[1] Wenn man als Orientierungspunkt für den Beginn der neuzeitlichen wahrheitsfähigen und prognosefähigen Texte Galileo Galilei (1564 – 1641) und Johannes Kepler ()1571 – 1630) nimmt , dann beginnt der Auftritt dieser Textform im 17./18. Jahrhundert. Siehe hier: https://de.wikipedia.org/wiki/Galileo_Galilei und hier: https://de.wikipedia.org/wiki/Johannes_Kepler
[2] UN. Secretary-General; World Commission on Environment and Development, 1987, Report of the World Commission on Environment and Development : note / by the Secretary General., https://digitallibrary.un.org/record/139811 (accessed: July 20, 2022) (In einem besser lesbaren Format: https://sustainabledevelopment.un.org/content/documents/5987our-common-future.pdf) Anmerkung: Gro Harlem Brundtland (ehemalige Ministerpräsidentin von Norwegen) war die Koordinatorin von diesem Report. 1983 erhielt sie den Auftrag vom Generalsekretär der UN einen solchen Report zu erstellen, 1986 wurde er übergeben und 1987 veröffentlicht. Dieser Text enthält die grundlegenden Ideen für alle weiteren UN-Texte.
Zitat aus dem Vorwort: „The fact that we all became wiser, learnt to look across cultural and historical barriers, was essential. There were moments of deep concern and potential crisis, moments of gratitude and achievement, moments of success in building a common analysis and perspective. The result is clearly more global, more realistic, more forward looking than any one of us alone could have created. We joined the Commission with different views and perspectives, different values and beliefs, and very different experiences and insights. After these three years of working together, travelling, listening, and discussing, we present a unanimous report.“ und „Unless we are able to translate our words into a language that can reach the minds and hearts of people young and old, we shall not be able to undertake the extensive social changes needed to correct the course of development.“
[3] Gerd Doeben-Henisch, 2016, Sind Visionen nutzlos?, URL: https://www.cognitiveagent.org/2016/10/22/sind-visionen-nutzlos/
[4] Zum Begriff der Evolution siehe hier: https://de.wikipedia.org/wiki/Evolution und hier: https://en.wikipedia.org/wiki/Evolution
7. EMPIRISCHE UND NACHHALTIG EMPIRISCHE THEORIE
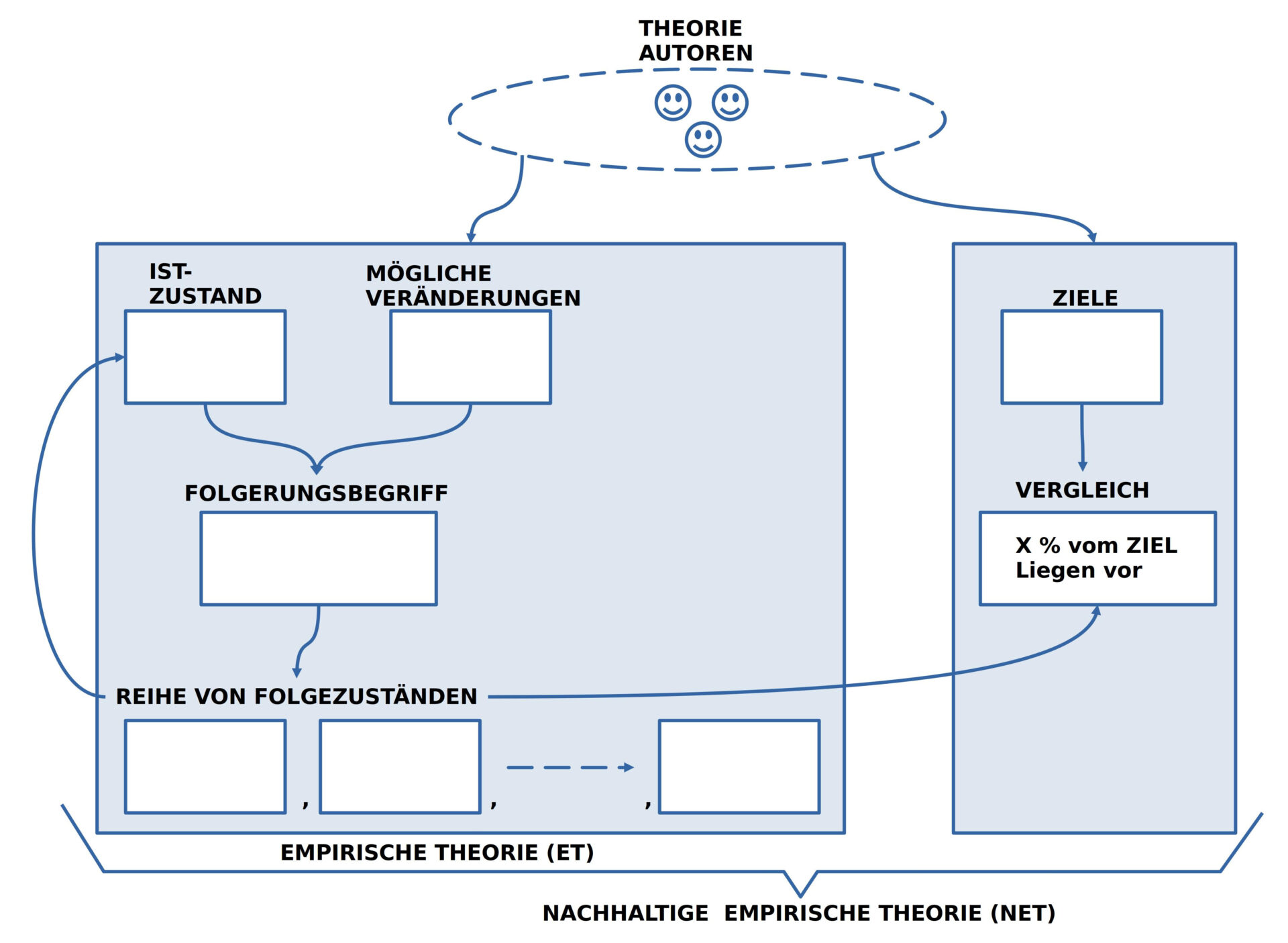
BILD 6 : Aktualisierter Begriff von ‚Empirischer Theorie (ET)‘ und ‚Nachhaltiger Empirischer Theorie (NET)‘
Zum ‚aktualisierten Begriff‘ einer empirischen und einer nachhaltig empirischen Theorie gehören die folgenden Elemente:
- Die Gruppe der ‚Theorie-Autoren‘ besteht prinzipiell aus allen Menschen, die in ihrer Alltagssprache kommunizieren. Dies ermöglicht von Anfang an maximale Diversität.
- Der engere Begriff der ‚Empirischen Theorie‘ umfasst die Elemente ‚IST-Zustand‘, ‚Veränderungs-Wissen‘ sowie einen ‚Folgerungsbegriff‘ in Form eines Wissens, wie man Veränderungswissen auf einen gegebenen Zustand anwendet.
- Das ‚Ergebnis einer Folgerung‘ ist ein ’neuer Folge-Zustand‘.
- Lässt sich eine Folgerung mehrfach vollziehen dann ensteht eine ‚Folge von Folgezuständen‘, die man heute auch als ‚Simulation‘ bezeichnen kann.
Der IST-Zustand umfasst eine Menge von Ausdrücken einer gewählten Alltagssprache, die so beschaffen sind, dass alle beteiligten Theorie-Autoren sich darüber einigen können, dass diese Ausdrücke unter den angenommenen Bedingungen ‚zutreffen‘, d.h. ‚wahr‘ sind.
Das Veränderungs-Wissen umfasst eine Menge von Ausdrücken, die Veränderungsprozesse beschreiben, die sich ebenfalls unter angegebenen Bedingungen von jedem überprüfen lassen.
Der Folgerungsbegriff ist ein Text, der eine Handlungsbeschreibung umfasst, die beschreibt, wie man eine Veränderungsbeschreibung auf eine gegebene IST-Beschreibung so anwendet, dass daraus ein neuer Text entsteht, der die Veränderung im Text enthält.
Eine empirische Theorie ermöglicht die Erzeugung von Texten, die mögliche Zustände in einer möglichen Zukunft beschreiben. Dies kann mehr als eine Option umfassen.
Im Alltag der Menschen reicht ein bloßes Wissen um ‚Optionen‘ aber nicht aus. Im Alltag müssen wir uns beständig Entscheiden, was wir tun wollen. Für diese Entscheidungen gibt es keine zusätzliche Theorie: für einen menschlichen Entscheidungsprozess ist es bis heute mehr oder weniger ungeklärt, wie er zustande kommt. Es gibt allerdings viele ‚Teil-Theorien‘ und noch mehr ‚Vermutungen‘.
Damit diese ’nicht-rationale Komponente‘ unseres alltäglichen Lebens nicht ‚unsichtbar‘ bleibt, wird hier der Begriff einer nachhaltigen empirischen Theorie vorgeschlagen, in dem zusätzlich zur empirischen Theorie eine Liste von Zielen angenommen wird, die von allen Beteiligten aufgestellt wird. Ob diese Ziele ‚gute‘ Ziele sind, kann man erst wissen, wenn sie sich ‚im weiteren Verlauf‘ ‚bewähren‘ oder eben nicht. Explizite Ziele ermöglichen daher einen ‚gerichteten Lernprozess‘. Explitit formulierte Ziele ermöglichen darüber hinaus eine kontinuierliche Kontrolle, wie sich der aktuelle Handlungsprozess mit Blick auf ein Ziel verhält.
Für die Umsetzung einer nachhaltigen Entwicklung sind nachhaltige empirische Theorien eine unverzichtbare Voraussetzung.
8. WAHRHEIT, PROGNOSE & TEXT-GENERATOREN
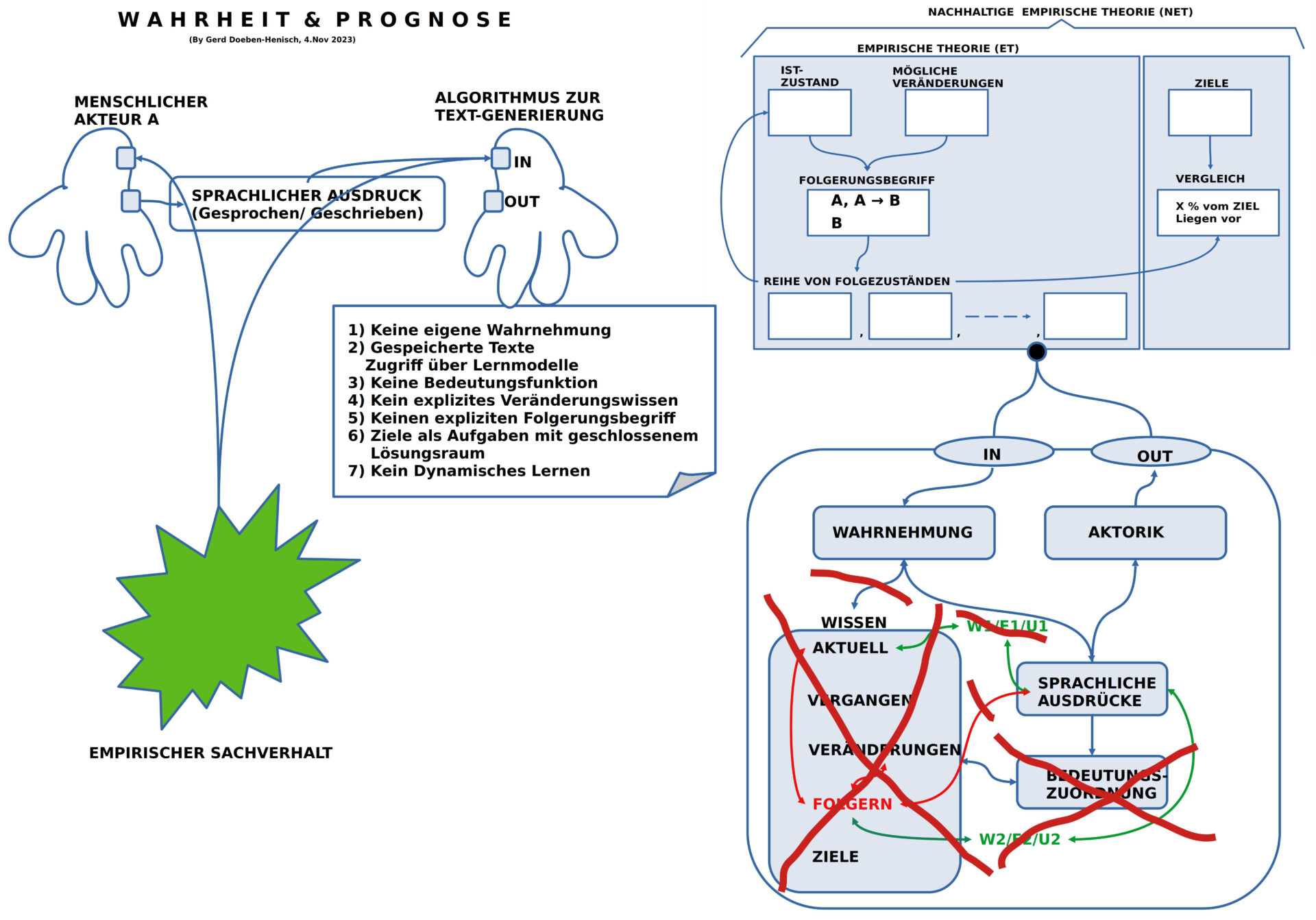
BILD 7 : Die potentielle Rolle von Text-Generatoren der Machart 2023 innerhalb eines wissenschaftlichen Diskurses
Für die Bewertung, welche Rolle Textgeneratoren aus dem Jahr 2023 innerhalb eines wissenschaftlichen Diskurses spielen können, kann man ein Gedankenexperiment (und dann natürlich auch real) durchführen, welche der Anforderungen eines wissenschaftlichen Diskurses, die zuvor erläutert worden sind, von einem Text-Generator erfüllt werden können. Das Bild Nr.7 ist eigentlich selbst-erklärend.
Das zentrale Argument besteht darin, dass Text-Generatoren des Jahrgangs 2023 über keinerlei Wissen verfügen, wie es der Mensch besitzt, nahezu keine Wahrnehmung (außer Texteingaben oder Spracheingaben) haben, und dementsprechend auch über keine Bedeutungsfunktion verfügen. Die Unfähigkeit zu ‚wahren Aussagen‘ oder auch der Fähigkeit, entscheiden zu können, ob etwas ‚wahr‘ ist oder nicht, fehlt ebenfalls vollständig.[1]
[1] Ron Brachman, Hector Levesque, Dieser KI können wir nicht trauen, Es gibt ein grundlegendes Problem in der Entwicklung der gegenwärtig angesagten KI-Systeme. Hier kommt ein Vorschlag, wie es besser geht. FAZ, Mo 13.Nov 2023, S.19 . Online (beschränkt) auch hier: https://www.faz.net/aktuell/wirtschaft/unternehmen/chatgpt-co-dieser-ki-koennen-wir-nicht-trauen-19308979.html, Anmerkung 1: Die beiden Autoren nehmen den Boom um chatGPT zum Anlass, vor der gesamten Künstlichen Intelligenz (KI) zu warnen. Sie fokussieren ihre Kritik auf einen Punkt: „Der aktuellen KI-Technologie kann man nicht trauen. … Obwohl sie auf der Grundlage riesiger Datenmengen trainiert werden … machen moderne KI-Systeme bizarre, dumme Fehler. Unvorhersehbare, unmenschliche Fehler.“ Und weiter: „Wir wissen nicht, wann diese Systeme das Richtige tun und wann sie versagen.“ Sie führen im weiteren Verlauf noch aus, dass die aktuelle Architektur dieser Systeme es nicht zulässt, heraus zu finden, was genau die Gründe sind, warum sie entweder richtig oder falsch urteilen. Mit Blick auf den Alltag diagnostizieren sie bei uns Menschen einen ‚gesunden Menschenverstand‘, ein Prototyp von ‚Rationalität‘, und diesen sehen sie bei den KI-Systemen nicht. Sie beschreiben viele Eigenschaften, wie Menschen im Alltag lernen (z.B. mit ‚Überzeugungen‘, ‚Zielen‘ arbeiten, mit ‚Konzepten‘ und ‚Regeln‘, mit ‚echten Fakten‘, …), und stellen fest, dass KI-Systeme für uns erst wirklich nützlich werden, wenn sie über diese Fähigkeiten nachvollziehbar verfügen. Anmerkung 2: Die Autoren sprechen es nicht explizit aus, aber implizit ist klar, dass sie die neuen Text-Generatoren wie chatGPT & Co zu jener KI-Technologie rechnen, die sie in ihrem Beitrag charakterisieren und kritisieren. Wichtig ist, dass Sie in ihrer Kritik Kriterien benutzen, die alltäglich vage sind (‚gesunder Menschenverstand‘), allerdings angereichert mit vielen Alltagsbeispielen. Letztlich machen ihre kritischen Überlegungen aber deutlich, dass es angesichts der neuen KI-Technologien an geeigneten und erprobten Meta-Modellen (‚transdisziplinär‘, ‚wissenschaftsphilosophisch‘, …) mangelt. Man ’spürt‘ ein Ungenügen mit dieser neuen KI-Technologie, kann auch viele Alltagsbeispiele aufzählen, aber es fehlt an einem klaren theoretischen Konzept. Ein solches scheint aber momentan niemand zu haben ….
9. Epilog
Diese Kurzfassung meines Vortags vom 10.November 2023 ist gedacht als ‚Basis‘ für die Erstellung eines umfassenderen Textes, in dem alle diese Gedanken weiter ausgeführt werden, dazu auch mit viel mehr Literatur und vielen realen Beispielen.
DER AUTOR
Einen Überblick über alle Beiträge von Autor cagent nach Titeln findet sich HIER.