Hier wieder ein kurzer Bericht zum Philosophiesommer 2016 in der Denkbar, Treffen am So 15.Mai 2016 (siehe die zugehörige Einladung)
Die Einleitung geriet etwas lang, vielleicht auch angesichts der vielen neuen Gesichter. Letztlich hielten wir aber unseren vorgeschlagenen Zeitplan ein. Sehr erfreulich war die breite Streuung der versammelten Kompetenzen, was sich dann in den Beiträgen widerspiegelte.
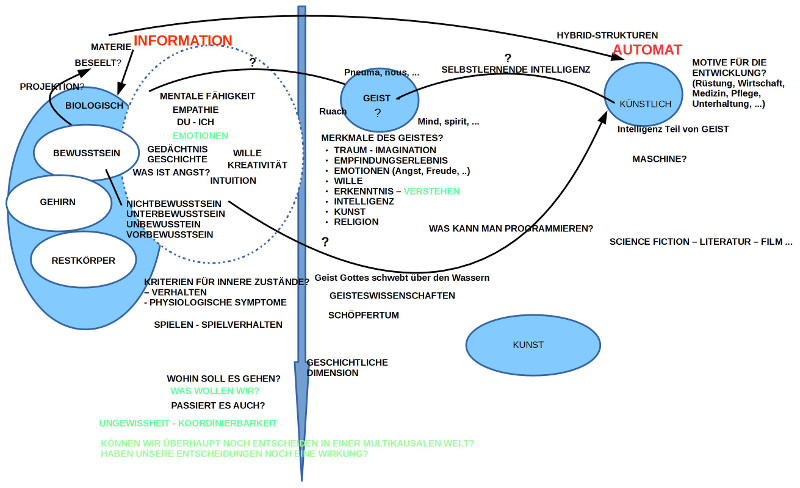
EINLEITUNG: SPANNUNGSFELD MENSCH – INTELLIGENTE MASCHINE
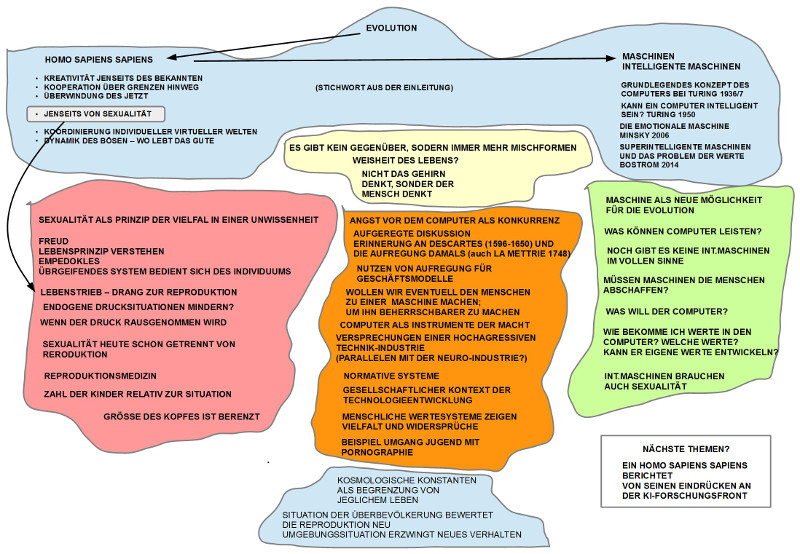
Ausgangspunkt war die spannungsvolle Diskussion vom letzten Treffen, bei dem zwar das Spannungsfeld Mensch einerseits, intelligente Maschinen andererseits, zur Sprache kam, wir uns aber nicht auf ein klares Thema für die Fortsetzung einigen konnten. Dies führte zur Formulierung von sechs Thesen zu Grundmerkmalen des biologischen Lebens, so wie sie sich am Beispiel des homo sapiens sapiens nach heutigem Kenntnisstand ablesen lassen. Diese Thesen sind gedacht als mögliche Orientierungspunkte für die weitere Diskussion des Spannungsfeldes Mensch – intelligente Maschinen.
STICHWORTE ZU INTELLIGENTE MASCHINEN
Analog zu den sechs Thesen zum biologischen Leben wurden ein paar Meilensteine zum Begriff der intelligenten Maschine in den Raum gestellt, an denen man das Reden über intelligente Maschinen fest machen kann.
STANDARD FÜR EINEN COMPUTER
Es wurde verwiesen auf den berühmten Artikel On Computable Numbers, with an Application to the Entscheidungsproblem. In: Proceedings of the London Mathematical Society. Band 42, 1937, S. 230–265, von Alan Mathison Turing (1912–– 1954), in dem er im Kontext eines mathematischen Beweises ein einfaches Gedankenkonstrukt einführte, was später zu seinen Ehren Turingmaschine genannt wurde. Dieses Gedankenkonstrukt, die Turingmaschine, ist bis heute der gedankliche Standard, die Norm, für Fragen der Entscheidbarkeit von Problemstellungen in der Computerwissenschaft. Nach heutigem Kenntnisstand kann kein realer Computer mehr als dieses gedankliche Konstrukt genannt Turingmaschine (und dies gilt auch für alle denkbaren reale Computer der Zukunft).
INTELLIGENTE MASCHINEN
Es war auch dann Turing, der 1950, als es gerade erste Ungetüme von Computer gab, die noch nicht allzu viel konnten, die Frage diskutierte, ob Computer einmal so intelligent werden könnten wie ein homo sapiens sapiens (siehe: Computing Machinery and Intelligence. In: Mind. LIX, Nr. 236, 1950, ISSN 0026-4423, S. 433–460 ). Er räsonierte darüber, dass Computer, wenn sie genauso lernen dürften wie Kinder, eigentlich auch alles wissen könnten, wie Kinder. Auf dem Weg zur intelligenten Maschine sah er weniger technische Probleme, sondern soziale psychologische: Menschen werden Probleme haben, intelligenten lernende Maschinen neben sich in ihrem Alltag zu haben.
EMOTIONALE MASCHINEN
Einer der einflussreichsten und wichtigsten Wissenschaftler der künstlichen Intelligenzforschung, Marvin Minsky (1927 – 2016) veröffentlichte wenige Jahre vor seinem Tod ein Buch über die emotionale Maschine ( The Emotion Machine, Simon & Schuster, New York 2006). Es ist – formal gesehen – kein streng wissenschaftliches Buch, aber dennoch bedenkenswert, da er hier im Lichte seines Wissens durchspielt, wie man die menschlichen Erfahrungen von diversen Gefühlszuständen mit dem zu diesem Zeitpunkt bekannten Wissen über Computer rekonstruieren – sprich erzeugen – könnte. Er sieht in solch einem Projekt kein prinzipielles Problem.(Anmerkung: Es könnte interessant sein, dieses Buch zusammen mit Psychologen und Psychotherapeuten zu diskutieren (evtl. ergänzt um Gehirnforscher mit einem psychologischen Training)).
SUPERINTELLIGENZ UND WERTE
Einen weiteren Aspekt bringt der in Oxford lehrende Philosoph Nick Bostrom ins Spiel. In seinem Buch Superintelligenz (Superintelligence. Paths, Dangers, Strategies. Oxford University Press, Oxford 2014) sieht er bzgl. der Möglichkeit, super-intelligenter Maschinen grundsätzlich auch keine grundsätzliche Schwierigkeit, wohl aber in der Wertefrage: nach welchen Werten (Zielgrößen, Präferenzen) werden sich diese super-intelligenten Maschinen richten? Werden sie sich gegen den Menschen wenden? Kann der Mensch ihnen solche Werte einspeisen, die diese super-intelligente Maschinen dem Menschen wohlgesonnen sein lassen? Er selbst findet auf diese Fragen keine befriedigende Antwort. Auch wird durch seine Analysen deutlich (was Bostrom nicht ganz klar stellt), dass die Wertefrage grundsätzlich offen ist. Die Menschen selbst demonstrieren seit Jahrtausenden, dass sie keine Klarheit besitzen über gemeinsame Werte, denen alle folgen wollen.
SECHS THESEN ZUM BIOLOGISCHEN LEBEN
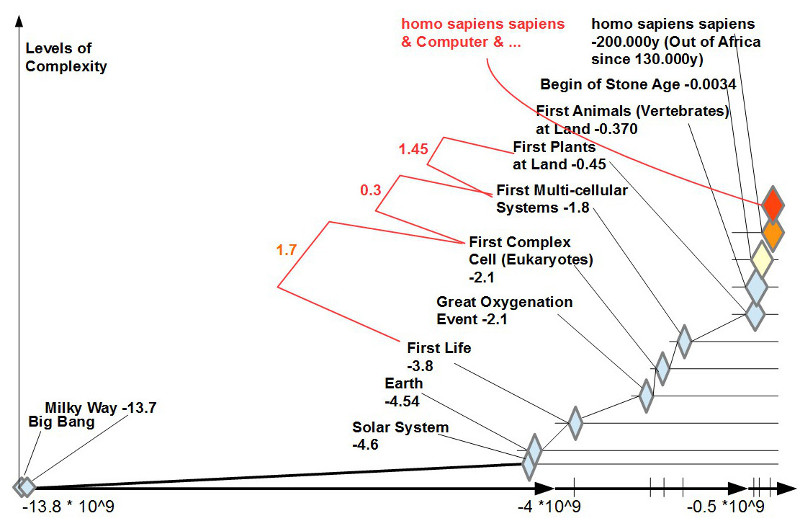
Angesichts des zuvor skizzierten ungebrochenen Glaubens an die Möglichkeiten einer Superintelligenz bei gleichzeitigem ungelösten Werteproblem bei den Menschen selbst stellt sich die Frage, ob wir Menschen als späte Produkte des biologischen Lebens nicht doch Eigenschaften an und in uns tragen, die mehr sind als eine beliebige Meinung. Aus der Vielzahl der neuesten wissenschaftlichen Erkenntnisse zum biologischen Leben und zum homo sapiens sapiens hatte Gerd Doeben-Henisch sechs in Form von Thesen ausgewählt und der Diskussion vorangestellt.
1. KREATIVITÄT JENSEITS DES BEKANNTEN: Die Explosion des Lebens fand statt auf der Basis eines Erfolgswissens aus der Vergangenheit (repräsentiert im DNA-Molekül) ohne Wissen um die Zukunft. Inmitten eines Nicht-Wissens wurde nicht nur das erprobte Wissen aus der Vergangenheit genutzt, sondern der Reproduktionsprozess erlaubte eine Vielzahl von Alternativen, die alle im Moment des Ereignisses das radikale Risiko des Scheiterns beinhalteten. Diese basale Form der Kreativität war die Methode, Leben zu finden, und das Risiko des Scheiterns der Preis: Ohne Tod kein Leben.
2. KOOPERATION ÜBR GRENZEN HINWEG: Die Explosion des Lebens fand statt durch Erlangung der Fähigkeit, mit völlig fremden Systemen (die oft lebensbedrohlich waren) in eine Kooperation geradezu galaktischen Ausmaßes einzutreten, die eine WinWin-Situation für alle Beteiligte bildete. Das Zustandekommen solcher WinWin-Situationen war in den ersten Milliarden Jahren zufällig; der Erhalt der gefundenen Vorteile beruhte auf der grundlegenden Fähigkeit des Lebens, Erfolge zu konservieren.
3. ÜBERWINDUNG DES JETZT: Solange die biologischen Systeme nicht über Gedächtnis, Abstraktionsfähigkeit, basalem Denken verfügten, waren sie im Jetzt der Sinneseindrücke gefangen. Es gab kein Gestern und kein Morgen. Nach der Explosion des Lebens ab ca. -450 Mio Jahren kam es zu einem einzigartigen Punkt: nach 13.8 Mrd Jahren konnte sich das Leben in Gestalt der Hominiden, speziell dann des homo sapiens sapiens, plötzlich selbst anschauen und verfügte ab da über das Potential, sich selbst zu verändern.
4. KOORDINIERUNG INDIVIDUELLER VIRTUELLER WELTEN: Mit der Überschreitung des Jetzt durch interne Konstruktionen entsteht im einzelnen Individuum ein rekonstruierendes virtuelles Abbild der realen Welt. Damit die vielen einzelnen dieses virtuelle Wissen gemeinsam nutzen können, braucht es neue, leistungsfähige Formen der Koordinierung durch symbolische Kommunikation. Erfindungen wie die Sprache, die Schrift, der Buchdruck usw. belegen eindrucksvoll, was symbolische Interaktion vermag.
5. JENSEITS VON SEXUALITÄT: Während die bisherige Form der Sexualität als Strategie der Mischung genetischer Informationen kombiniert mit endogenem Handlungsdruck bei den handelnden Individuen über Jahrmillionen den Erhalt des Lebens offensichtlich ermöglicht hat, führen die neuen Lebensverhältnisse der großen Siedlungsdichten und der drohenden Überbevölkerung zur Frage, wie sich der Mensch von den endogenen Handlungsdrücken hinreichend befreien kann. Mann – Frau war gestern?
6. DYNAMIK DES BÖSEN – WO LEBT DAS GUTE: tiefsitzende Triebstrukturen im Menschen (Macht, Geld, Dünkel, …) sind seit Jahrtausenden bekannt. Mit den neuen globalen Informationstechnologien können sie sich schneller und effektiver im globalen Maßstab organisieren als nationale politische Systeme. Globale Kartelle des Machtmissbrauchs und der der Kriminalität bedrohen die neuzeitlichen Freiheitsansätze des Kreativen (neben anderen Faktoren).
FREIER DISKURS
Bei diesem breiten Spektrum des Themas war klar, dass nicht alle angesprochenen Aspekte gleichzeitig diskutiert werden konnten.
SEXUALITÄT
Die ersten Gesprächsbeiträge griffen die These zur Sexualität auf. Eher grundsätzliche Überlegungen thematisierten, dass Sexualität als ein grundlegendes und übergreifendes Prinzip zu sehen ist; die einzelnen Individuen sind hier nur – in gewisser Weise – nur ‚Marionetten‘ in dem großen Spiel des Lebens. Das Leben will überleben, der einzelne muss entsprechend funktionieren. Dass die biologisch vorgegebene eingebaute endogene Drucksituation im Laufe der Jahrtausende innerhalb der unterschiedlichen Kulturen mit ihren Wertesystemen zu vielfältigen Formen der Regulierungen geführt hat (meist zu Lasten der Frauen), ist manifest. Versuche der Menschen, die strenge Kopplung zwischen Sexualität und Reproduktion zu lockern gab es immer. Erst in neuester Zeit verfeinerten sich die Techniken, bieten sich Möglichkeit in die chemischen oder gar genetischen Prozesse einzugreifen bzw. durch die Reproduktionsmedizin die Reproduktion mehr und mehr aus dem biologischen System auszulagern. War schon immer die Anzahl der Kinder ein Indikator für den aktuellen Wohlstand, so führt heute die zunehmende Bevölkerungsdichte erneut zu Überlegungen, den bisherigen Reproduktionsmechanismus zu verändern. Für alle die neuen Maßnahmen und Technologien zur Veränderung der Reproduktion spielt der Einsatz von Computern eine immer größere Rolle. Zugleich wird der Computern für die Sexualität in Form von Sexrobotern auch immer mehr eingesetzt. Bräuchten super-intelligente Maschinen auch ein Äquivalent zur Sexualität, um sich zu vermehren?
INTELLIGENTE MASCHINEN
Die Position der intelligenten Maschinen blieb auffällig abstrakt. Was können sie eigentlich wirklich leisten? Richtig intelligente Maschinen scheint es noch nicht wirklich zu geben. Generell wurde nicht ausgeschlossen, dass super-intelligente Maschinen eine neue Variante der Evolution ermöglichen können. Haben diese super-intelligente Maschinen dann einen eigenen Willen? Würden sie aus sich heraus zu dem Punkt kommen, dass sie die Menschen abschaffen würden? Können wir den super-intelligente Maschinen solche Werte einpflanzen, dass sie den Menschen grundsätzlich wohlgesonnen sind (hier sei erinnert an die vielen geistreichen Science Fiction von Isaak Asimov (1919 – 1992), der unter anderem die Robotergesetze erfunden hatte, die genau diese Idee umsetzen sollten: menschenfreundliche Roboter ermöglichen).
NICHT SCHWARZ-WEISS DENKEN
Im Gespräch zeichnete sich auch eine Position ab, die viele Argumente auf sich vereinte, nämlich jene, die weniger konfrontativ Mensch und super-intelligente Maschinen gegenüberstellt, sondern von einer symbiotischen Wechselbeziehung ausgeht. Der Mensch entwickelt schrittweise die neuen Technologien, und in dem Masse, wie diese real erfahrbar werden, beginnt die ganze Gesellschaft, sich damit auseinander zu setzen. Systemisch gibt es damit beständige Rückkopplungen, die – falls die gesellschaftliche Dynamik (Öffentlichkeit, freie Meinung, Diskurs..) intakt ist – nach Optimierungen im Verhältnis zwischen Menschen und Maschinen sucht. Natürlich gibt es massive wirtschaftliche Interessen, die versuchen, die neuen Möglichkeiten für sich zu nutzen und versuchen, alle Vorteile einseitig zu akkumulieren; es ist dann Aufgabe der ganzen Gesellschaft, dieser Tendenz entsprechend entgegen zu wirken. Dabei kann es sehr wohl zu Neujustierungen bisheriger Normen/ Werte kommen.
WEISHEIT DES LEBENS
Wenn man bedenkt, welch ungeheuren Leistungen das biologische Leben seit 3.8 Mrd Jahren auf der Erde vollbracht hat, wie es Lebewesen mit einer gerade zu galaktischen Komplexität geschaffen hat (der Körper des homo sapiens sapiens hat nach neuen Schätzungen ca. 34 Billionen (10^12) Körperzellen (plus noch mehr Bakterien in und am Körper), die alle als Individuen im Millisekundentakt zusammenwirken, während dagegen die Milchstraße, unsere Heimatgalaxie, ca. nur 100 – 300 Mrd. Sonnen besitzt), dann kann man nicht grundsätzlich ausschließen, dass diese Leben implizit über eine ‚Weisheit‘ verfügt (man könnte auch einfach von ‚Logik‘ sprechen), die möglicherweise größer, tiefer umfassender ist, als jede denkbare Superintelligenz, weil diese, wann und wo auch immer, nicht von außerhalb des Systems entsteht, sondern innerhalb des Systems.
NÄCHSTES THEMA
Da viele Teilnehmer sagten, dass sie sich unter diesen intelligenten Maschinen immer noch nichts Rechtes vorstellen können, wurde ein anwesender Experte für intelligente Maschinen (aus der Gattung homo sapiens sapiens) gebeten, für das nächste Treffen eine kleine Einführung in die aktuelle Situation zu geben.
Ein Überblick zu allen bisherigen Themen des Philosophiesommers (und seiner Vorgänger) nach Titeln findet sich HIER.