Journal: Philosophie Jetzt – Menschenbild
ISSN 2365-5062, 22.Februar 2021
URL: cognitiveagent.org, Email: info@cognitiveagent.org
Autor: Gerd Doeben-Henisch (gerd@doeben-henisch.de)
(Letzte Änderung: 25.März 2021)
KONTEXT
In diesem Beitrag soll das Konzept einer praktischen kollektiven Mensch-Maschine Intelligenz by design weiter entwickelt werden. Der unmittelbar vorhergehende Beitrag findet sich hier. In diesem Text geht es jetzt darum, das Anwendungsszenario explorative Entwicklung unter Einbeziehung einer kontinuierlichen Simulation [ESBD] zu beschreiben.
Bisher zum Thema veröffentlicht:
- 18.02., 12:05 PRAKTISCHE KOLLEKTIVE MENSCH-MASCHINE INTELLIGENZ by design. MMI Analyse. Teil 2
- 16.02., 17:17 PRAKTISCHE KOLLEKTIVE MENSCH-MASCHINE INTELLIGENZ by design. MMI Analyse. Teil 1
- 15.02., 09:21 PRAKTISCHE KOLLEKTIVE MENSCH-MASCHINE INTELLIGENZ by design. Problem und Vision
- 12.02., 18:14 PRAKTISCHE KOLLEKTIVE MENSCH-MASCHINE INTELLIGENZ by design
INFOGRAFIK
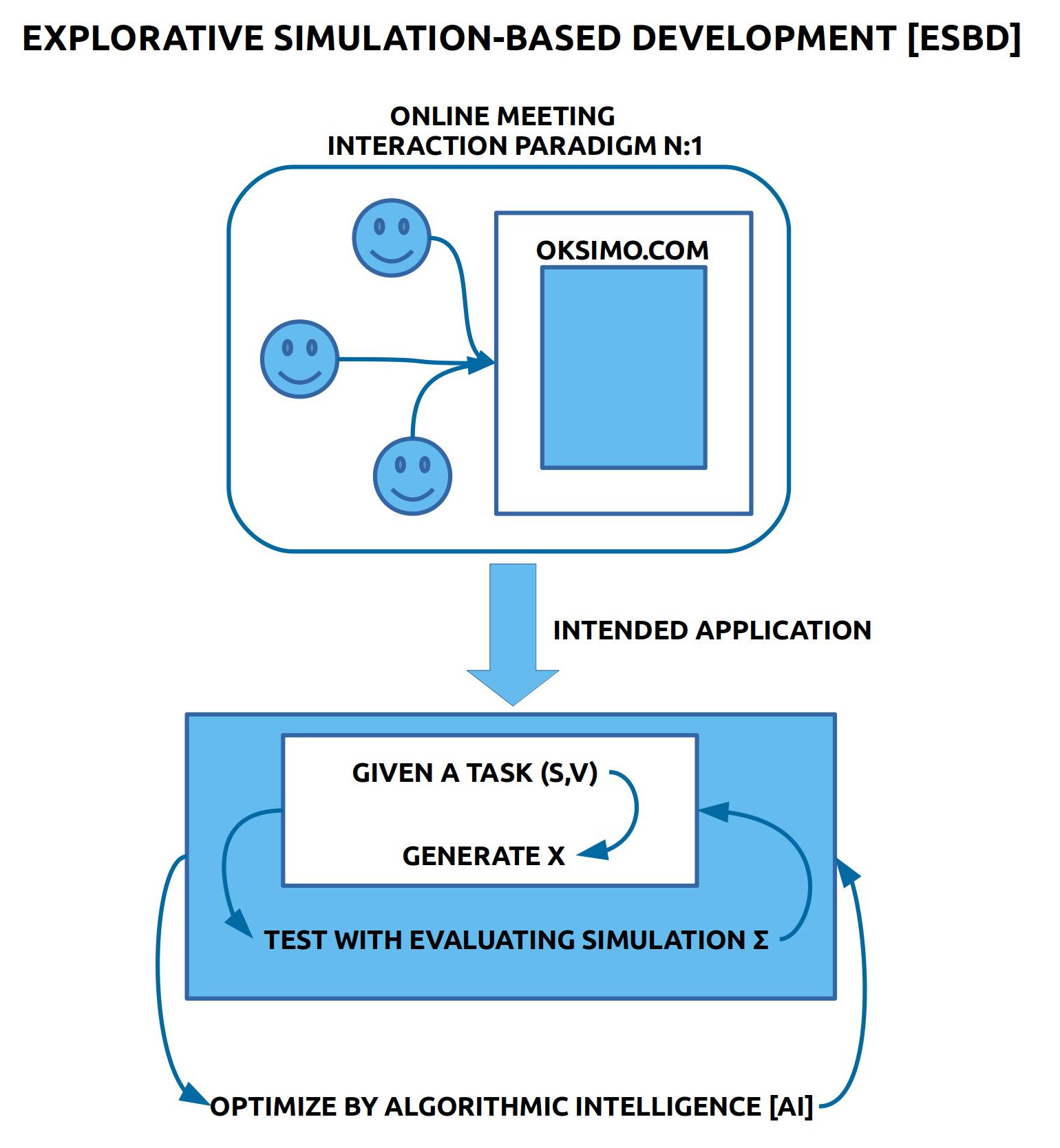
ESBD: ÜBERBLICK
Die explorative simulations-basierte Entwicklung geht davon aus, dass eine Gruppe von Experten sich auf eine Ausgangslage S und auf eine Vision V geeinigt haben. Beide zusammen, also S und V, werden als Aufgabe (S,V) begriffen. Gesucht wird nach einer Menge von Veränderungsregeln X, deren Anwendung eine Folge von Zuständen/ Situationen <S.0, S.1, …, S.n> erzeugt, die letztlich einen Weg bilden, der von S nach V führt. In dieser Folge von Zuständen gilt, dass ein beliebiger Nachfolgezustand S.i aus einem vorhergehenden Zustand S.i-1 dadurch entstanden ist, dass mindestens eine Veränderungsregel X.i aus X auf den vorhergehenden Zustand S.i-1 angewendet worden ist, was dann zur Entstehung von S.i geführt hat. Die Anwendung von Veränderungsregeln X auf einen gegebenen Zustand S können entweder von den Experten selbst ‚per Hand‘ (‚manuell‘) ausgeführt werden oder automatisch durch den eingebauten Simulator ∑. Die Anwendung des Simulators auf die Aufgabe (S,V) mittels der Regeln X wird geschrieben: ∑(S,V,X) = SQ(S,V,X,∑) = <S.0, S.1, …, S.n>. Neben der Folge der Zustände zeigt der Simulator zu jeder neuen Nachfolgesituation auch an, wie viel % der Ausdrücke aus der Vision schon im aktuellen Zustand S.i enthalten sind. Falls verfügbar, kann man zusätzlich zum Simulator noch die algorithmische Intelligenz ⊪ aktivieren, um die wichtigsten guten Lösungen anzuzeigen.
AUSGANGSLAGE S
Die Ausgangslage S wird gebildet durch eine Menge von Ausdrücken E einer Alltagssprache L (z.B. Deutsch, Englisch, Spanisch, …). Ein einzelner Ausdruck E.i hat als solcher keine Bedeutung. Es wird aber vorausgesetzt, das derjenige, der diesen Ausdruck E.i eingibt, aufgrund seines Sprachverständnisses mit diesem Ausdruck E.i eine Bedeutungsvorstellung B(E.i) verknüpft, von der angenommen werden kann, dass diese sich auf eine beobachtbare Eigenschaft B(E.i)* in einer Alltagssituation S* beziehen lässt oder aber sich in andere Ausdrücke E‘ übersetzen lässt, von denen dies gilt. Die Menge der Ausdrücke E in der Zustandsbeschreibung/ Situationsbeschreibung S korrespondiert danach einer Menge von beobachtbaren Eigenschaften in einer Alltagssituation S* zu einem gewählten Zeitpunkt TS, also S*(TS). Unter Voraussetzung dieses Bezuges zu einer Alltagssituation S* kann gesagt werden, dass die Menge der Ausdrücke E in der Beschreibung S = {E.1, E.2, …, , E.n} als empirisch zutreffend zum Zeitpunkt T angenommen werden; eine andere Formulierung wäre, dass diese Ausdrücke von S als wahr bezeichnet werden. Sobald die Menge der Ausdrücke einer Situation S sich zur Situation S‘ ändert, weil mindestens ein Ausdruck in S‘ anders ist als in S (z.B. die Zeitmarke T‘), wird angenommen werden, dass sich auch die korrespondierende Alltagssituation geändert hat.
Im Rahmen einer Aufgabenstellung (S,V) soll die Ausgangslage S eine reale Situation in einem Alltag beschreiben, die alle Beteiligten als real gegeben annehmen. Die Ausgangslage S kann, aber muss nicht, auch explizit solche Eigenschaften E* enthalten, die die Beteiligten als Verbesserungswürdig klassifizieren. In welchem Sinne diese verbesserungswürdigen Zustände E* mit Blick auf eine Zukunft verbessert werden sollen, wird in einem separaten Visionstext V beschrieben.
Ein Startzustand S kann beliebig erweitert werden. Es kann auch parallel verschiedene Startzustände {STs.1, …, STs.n} geben, die thematisch unterschiedliche Aspekte beleuchten oder verschiedenen Raumgebiete betreffen. Verschiedene Startzustände können nach Bedarf ‚per Knopfdruck‘ zu einem einzigen Zustand S zusammen gefasst werden.
VISION V
Ohne die Angabe eines Zustands SF für einen Zeitpunkt TF > TS, der größer ist als der Startzeitpunkt TS, gibt es in der möglichen Entwicklung des Startzustands S keine Entwicklung in eine bestimmte Richtung. Da dieser Zustand SF in der Zukunft liegt, nicht gegenwärtig ist, haben die Bedeutungen B(SF) der Ausdrücke im Zustand SF keine externe, beobachtbare Entsprechung im Alltag. Deshalb wird diese für die Zukunft angenommene Situation SF auch Vision genannt. Allerdings wird unterstellt, dass die Ausdrücke E von SF in der Zukunft ab einem Zeitpunkt TF zutreffen werden, d.h. ab diesem Zeitpunkt wahr sein werden. Es ist dabei nicht ausgeschlossen, dass dieser Fall schon vor dem angezielten Zeitpunkt TF stattfinden kann. Ebenso kann er sich verzögern.
Auch für den Visionstext gilt — wie im Falle des Startzustands S –, dass er beliebig erweitert werden kann oder dass es parallel verschiedene Visionstexte gibt, die nach Bedarf ‚per Knopfdruck‘ zu einem vereinigt werden.
Je mehr Ausdrücke der Visionstext V umfasst, um so differenzierter kann man die Zielsituation beschreiben.
KONSTRUIEREN DER VERÄNDERUNGSREGELN X
Im Kontext einer Folge von beschreibbaren Situationen kann man die Veränderungen in der Form von Veränderungs-Regeln fassen: Man sagt: wenn die Bedingung C in einer aktuellen Situation S erfüllt ist, dann sollen mit der Wahrscheinlichkeit π die Aussagen Eplus der Situation S hinzugefügt werden, um die Nachfolgesituation S‘ zu generieren, und die Aussagen Eminus sollen von S weggenommen werden, um die Nachfolgesituation S‘ zu generieren.
Man kann für jede Ausgangslage S beliebig viele Veränderungsregeln X erstellen. Insofern gilt XS = {XS.1, …, XS.n}. Ist eine bestimmte Situation S.i im Verlauf gegeben, dann kann es mehr als eine Veränderungsregel geben, die aus X zutrifft, also XS.i ⊆ X. In diesem Fall werden alle diese Regel XS.i auf S.i angewendet XS.i(S.i) = S.i+1. Die Reihenfolge der Regeln aus XS.i wird für die Anwendung auf S.i jeweils per Zufall bestimmt.
TESTEN DER VERÄNDERUNGSREGELN X
Da sich die möglichen Auswirkungen der Regeln in ihrer Anwendung auf einen gegeben Zustand S mit zunehmender Zahl und wachsender Komplexität von S (und auch V) immer schwerer ‚im Kopf‘ vorstellen lassen, kann man sich vom eingebauten Simulator ∑ anzeigen lassen, welche Folge von Situationen <S.1, S.2, …> entsteht und wie weit diese schon die angezielte Vision V enthalten.
Durch diese Möglichkeit der jederzeit möglichen Simulation hat die Konstruktion eines Weges von S nach V mittels Veränderungsregeln X einen spielerischen Charakter.
UNTERSTÜTZUNG DURCH ALGORITHMISCHE INTELLIGENZ ⊪α
Liegt eine Aufgabe (S,V) vor zusammen mit einer Menge von Veränderungsregeln X dann kann der eingebaute Simulator ∑ daraus eine Sequenz der Art ∑(S,V,X) = SQ.i = <S.1, S.2, …, S.n> erzeugen, wobei jede einzelne Situation S.i in dieser Folge mit einer Bewertung indiziert ist. Der Simulator ∑ funktioniert in diesem Zusammenhang wie eine logische Folgerungsbeziehung ⊢, geschrieben: S,V,X ⊢∑ SQ.i.
Im allgemeinen Fall kann man mehr als eine Sequenz SQ.i mit Hilfe von ⊢∑ aus {S,V,X} ableiten. Schreibt man sich einen Algorithmus α der alle möglichen Ableitungen durchführt, die z.B. einen bestimmten minimalen Bewertungsindex haben und die z.B. die kürzesten Sequenzen sind, dann entsteht eine Menge SQ+, die alle diese Sequenzen enthält. Dieser Algorithmus α funktioniert dann auch wie eine Ableitung; diese Form der Ableitung nennen wir hier algorithmische Intelligenz und schreiben ihre Anwendung: S,V,X ⊪α SQ+ [1]
Statt also alle möglichen Simulationen selbst durchführen zu müssen, können die Experten mit Hilfe der algorithmischen Intelligenz α mit Feinjustierung von Parametern gezielt nach der Menge der möglichen Ableitungen suchen, die diese Parameter erfüllen. Dies kann eine Menge Arbeit ersparen und vor allem, es kann helfen relativ schnell, ein tieferes Verständnis des Problemraumes zu bekommen.
QUELLENNACHWEISE und ANMERKUNGEN
[1] Im Englischen gibt es für den Begriff ‚Künstliche Intelligenz [KI]‘ (bzw. ‚Maschinelles Lernen [ML]‘) eine Vielzahl von Begriffen — z.B. ‚Artificial Intelligence [AI]‘, “Machine Learning [ML]‘, ‚Computational Intelligence [CI]‘ , ‚Algorithmic Intelligence [AI]‘, ‚Embodied Intelligence‘, …) — die alle mehr oder weniger nicht wirklich definiert sind. Zusätzlich verwirrend ist die Tatsache, dass wir Menschen den Begriff ‚Intelligenz‘ eigentlich nur aus dem Kontext menschlichen Verhaltens — mittlerweile auch ausgedehnt auf verschiedene Formen tierischen und pflanzlichen Verhaltens — kennen. Hier haben Biologie und Psychologie schon seit Jahrzehnten einigermaßen brauchbare Definitionen von ‚Intelligenz‘ bereit gestellt (die man kritisieren kann, aber sie sind immerhin da und sie funktionieren). Die Vielstimmigkeit der technischen Intelligenzbegriffe bietet dagegen eher eine Dissonanzwolke. Ein zusammenfassendes, alle Aspekte integrierendes Konzept von ‚Intelligenz‘ — auch in den Vergleichen — wäre für uns alle extrem hilfreich. In dieser Situation habe ich mich für den Begriff ‚Algorithmische Intelligenz‘ entschieden, da er der Tatsache Rechnung trägt, dass der Kern aller technischen Intelligenzleistungen in der Software (= Computerprogramm, Algorithmus) lokalisiert ist. Ob man nun einen bestimmten Algorithmus als ‚Intelligent‘ oder ’nicht intelligent‘ bezeichnen will, hängt dann davon ab, welche verhaltensrelevanten Eigenschaften man mit diesem Algorithmus in Zusammenhang bringen kann. Am Beispiel des oksimo-Paradigmas lässt sich sehr genau ein sogenannter Problemraum definieren, der ‚by design‘ als Abfallprodukt menschlichen Verhaltens entsteht, und in diesem Problemraum gibt es Suchprozesse und Bewertungsprozesse, die zusammen die Identifizierung eines — von Menschen definierten — interessanten Teilraumes ermöglichen. Dieser Prozess von Suchen + Bewerten + Auszeichnung einer Teilmenge wird hier mit dem Begriff der algorithmischen Intelligenz verknüpft. Ob und wie sich dieser Begriff von algorithmischer Intelligenz mit den Intelligenbzbegriffen der Biologen und Psychologen vergleichen lässt, soll demnächst diskutiert werden.
FORTFÜHRUNG DIESER GEDANKEN
(Letzte Änderung: 25.März 2021)
Die oben beschriebenen Gedanken finden eine Fortsetzung wie folgt:
- Im eJournal uffmm.org einmal auf der Seite https://www.uffmm.org/2020/04/02/case-studies/ mit vier Beiträgen
- im eJournal uffmm.org in der neuen Rubrik Philosophy of Science mit einer ganzen Folge von Beiträgen.
- im neuen Anwendungsblog oksimo.org der oksimo Software.
Das Thema wird daher in diesem eJournal Philosophie Jetzt. Auf der Suche … nicht mehr weiter behandelt.
DER AUTOR
Einen Überblick über alle Beiträge von Autor cagent nach Titeln findet sich HIER.
