Journal: Philosophie Jetzt – Menschenbild
ISSN 2365-5062, 18.Februar 2018
URL: cognitiveagent.org
Email: info@cognitiveagent.org
Autor: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
Frankfurt University of Applied Sciences
Institut für Neue Medien (INM, Frankfurt)
INHALT
I Kontext … 1
II Die Größen … 2
III Ermittelte Sachverhalte … 3
IV Philosophische Anmerkungen … 4
IV-A Zusammenhang durch Funktionen … 4
IV-B Gehirn so winzig … 5
IV-C Bewusstsein: Was ist das? … 5
V Anhang: Rechenvorschriften … 6
VI Anhang: Ausführung von Rechenvorschriften … 7
Quellen
THEMA
Die Diskussion um die neue Frage nach dem Menschen angesichts der fortschreitenden Digitalisierung hat erst begonnen. Im vorausgehenden Beitrag zur ’Informellen Kosmologie’ wurde der große evolutionsbiologische Zusammenhang skizziert. Hier ein Hinweis auf die unvorstellbare Komplexität eines einzelnen menschlichen Körpers im Vergleich zur Milchstraße, und was dies bedeuten kann (ansatzweise).
I. KONTEXT
Die Diskussion um die neue Frage nach dem Menschen angesichts der fortschreitenden Digitalisierung hat erst begonnen. Im vorausgehenden Beitrag zur ’Informellen Kosmologie’ ist der große evolutionsbiologische Zusammenhang skizziert worden: nach ca. 9.6 Milliarden Jahren ohne biologische Lebensformen (soweit wir
wissen) bildeten sich vor ca. 4 Milliarden Jahren einfache Lebensformen auf der Erde (Bakterien, Archaeen), die dann innerhalb von 2 Milliarden Jahren die Erde in allen Winkeln chemisch so verändert haben, dass es zu einer Sauerstoffatmosphäre kommen konnte. Trotz der damit einhergehenden globalen Vereisung der Erde (’snowball earth’) für viele Millionen Jahre konnten sich dann aber komplexe Lebensformen bilden, die im Verlauf von weiteren 2 Milliarden Jahren dann – trotz vieler weiterer globaler Katastrophen – die Lebensform homo sapiens hervorgebracht
haben, der dann die Erde ein weiteres Mal flächendeckend erobert und kolonisiert hat. Dieser Prozess befindet sich aktuell in einer Phase, in der der homo sapiens aufgrund seiner erweiterten Denk- und Kommunikationsfähigkeiten das ’Prinzip des Geistes’ in Form von – aktuell noch sehr primitiven – ’lernfähigen und intelligenten Maschinen’ in
eine neue Dimension transformiert.
Von den vielen Fragen, die sich hier stellen, sei hier heute nur ein winziger Teilaspekt aufgegriffen, der aber dennoch geeignet erscheint, das Bild des Menschen von sich selbst wieder ein kleines Stück der ’Realität’ anzunähern.
Der winzige Teilaspekt bezieht sich auf die schlichte Frage nach der ’Komplexität’ eines einzelnen menschlichen Körpers. Natürlich gibt es zahlreiche Lehrbücher zur ’Physiologie des Menschen’ (Z.B. Birbaumer (2006) [BS06]) , in denen man über viele hunderte Seiten zur Feinstruktur des Körpers finden kann. Ergänzt man diese Bücher um Mikrobiologie (Z.B. Alberts (2015) [AJL + 15]) und Genetik, dann ist man natürlich sehr schnell in einem Denkraum, der die einen in Ekstase versetzen kann, andere möglicherweise erschaudern lässt angesichts der unfassbaren Komplexität von einem einzelnen Körper der Lebensform homo sapiens.
Hier soll der Blick mittels eines spielerischen Vergleichs auf einen winzigen Aspekt gelenkt werden: ein versuchsweiser Vergleich zwischen einem einzelnen menschlichen Körper und der Milchstraße, unserer ’Heimatgalaxie’ im Universum.
II. DIE GRÖSSEN
Im ersten Moment mag man den Kopf schütteln, was solch ein Vergleich soll, wie man solche so unterschiedliche Dinge wie einen menschlichen Körper und die Milchstraße vergleichen kann. Doch hat die neuzeitliche Erfindung der Mathematik die Menschen in die Lage versetzt, auf neue abstrakte Weise die Phänomene der Natur jenseits
ihrer augenscheinlichen Reize neu zu befragen, zu beschreiben und dann auch zu vergleichen. Und wenn man auf diese Weise einerseits die Komplexität von Galaxien beschreibt, unabhängig davon auch die Komplexität von biologischen Lebensformen, dann kann einem auffallen, dass man auf abstrakter Ebene sehr wohl eine Beziehung
zwischen diesen im ersten Moment so unterschiedlichen Objekte feststellen kann.
Der ’gedankliche Schlüsselreiz’ sind die ’Elemente’, aus denen sich die Struktur einer Galaxie und die Struktur des Körpers einer biologischen Lebensform bilden. Im Falle von Galaxien sind die primären Elemente (der Astrophysiker) die ’Sterne. Im Fall der Körper von biologischen Lebensformen sind es die ’Zellen’.
Im Alltag spielen die einzelnen Zellen normalerweise keine Rolle; wir sind gewohnt von uns Menschen in ’Körpern’ zu denken, die eine bestimmte ’Form’ haben und die zu bestimmten ’Bewegungen’ fähig sein. Irgendwie haben wir auch davon gehört, dass es in unserem Körper ’Organe’ gibt wie Herz, Leber, Niere, Lunge, Magen, Gehirn usw.,
die spezielle Aufgaben im Körper erfüllen, aber schon dies sind gewöhnliche ’blasse Vorstellungen’, die man der Medizin zuordnet, aber nicht dem Alltagsgeschehen.
Tatsache ist aber, dass alles, auch die einzelnen Organe, letztlich unfassbar große Mengen von individuellen Zellen sind, die jeweils autonom sind. Jede Zelle ist ein individuelles System, das von all den anderen Zellen um sich herum nichts ’weiß’. Jede Zelle tauscht zwar vielfältige chemische Materialien oder auch elektrische Potentiale mit der Umgebung aus, aber eine Zelle ’weiß’ darüber hinaus nichts von ’dem da draußen’. Schon der Begriff ’da draußen’ existiert nicht wirklich. Und jede Zelle agiert autonom, folgt ihrem eigenen Programm der Energiegewinnung und der Vermehrung.
Schon vor diesem Hintergrund ist es ziemlich bizarr, wie es möglich ist, dass so viele Zellen im Bereich zwischen Millisekunden, Sekunden, Minuten, Stunden, Tagen usw. miteinander kooperieren, so, als ob sie alle einem geheimnisvollen Plan folgen würden.
Fragt man dann, wie viele von solchen Zellen dann im Bereich eines menschlichen Körpers aktiv sind, wird das Ganze fast unheimlich. Das Unheimliche beginnt schon bei der Frage selbst. Denn unsere Forscher haben bis heute keine wirklich ’harte’ Zahlen zur Anzahl der Zellen im Körper des Menschen, allerdings erste Annäherungen, die sich beständig weiter verfeinern.
Für den Bereich des menschlichen Körpers habe ich die Darstellung von Kegel (2015) [Keg15] benutzt, der sowohl Abschätzungen für die Körperzellen im engeren Sinne bietet (ca. 37.2 Billionen (32.7^12 )) wie auch für die Bakterien im Körper (ca. 100 Billionen (100^12 )).
Innerhalb des Körpers nimmt das Gehirn für manche Eigenschaften eine besondere Stellung ein. Auch hier zeigt die Literatur, dass eine Abschätzung der Anzahl der Zellen schwierig ist (Messverfahren generell, dann die unterschiedlichen Strukturen in verschiedenen Gehirnarealen). Nach dem neuesten Übersichtsartikel zum Thema über die letzten
150 Jahre von Bartheld et.al. (2016) [vBBHH16] konvergieren die Schätzungen aktuell dahingehend, dass das Verhältnis der Gliazellen zu den Neuronen weitgehend konstant erscheint mit 1:1 und dass sich die Zahl der Gliazellen zwischen 40-130 Milliarden bewegt. Dabei gilt nach neuesten Erkenntnissen, dass sich die Gesamtzahl der Gehirnzellen nach dem anfänglichen Aufbau altersabhängig nicht (!) kontinuierlich abbaut. Dies geschieht nur bei spezifischen Krankheiten. Für die Modellrechnung habe ich dann die Zahl der Neuronen und Gliazellen mit jeweils 100 Milliarden angenommen (damit möglicherweise zu hoch).
Auch bei der Abschätzung der Anzahl der Sterne in der Milchstraße stößt man auf erhebliche Probleme. Ein kleiner Einblick in die Problematik findet sich in einem Artikel der NASA von 2015 [Mas15]. Viele Schätzungen konvergieren aktuell im Bereich zwischen 100 – 400 Milliarden Sterne, aber es könnten möglicherweise viel mehr sein. Die Erkenntnislage ist noch sehr unsicher. Für den geplanten Vergleich habe ich jetzt einfach mal angenommen, es seien 300 Milliarden. Sollten irgendwann bessere Zahlen verfügbar sein, dann könnte man diese stattdessen eintragen.
Die Idee ist, ein erstes ’Gefühl’ dafür zu bekommen, wie sich die Komplexität der ’Himmelskörper’ zur Komplexität von biologischen Lebensformen verhält.
III. ERMITTELTE SACHVERHALTE
Die Rechenvorschriften, mit denen ich gerechnet habe sowie die Ausführung dieser Rechenvorschriften finden sich unten im Anhang.
Führt man die ’Rechnungen durch und überträgt die Zahlen (grob) in eine Zeichnung, dann er gibt sich folgendes Bild 1:
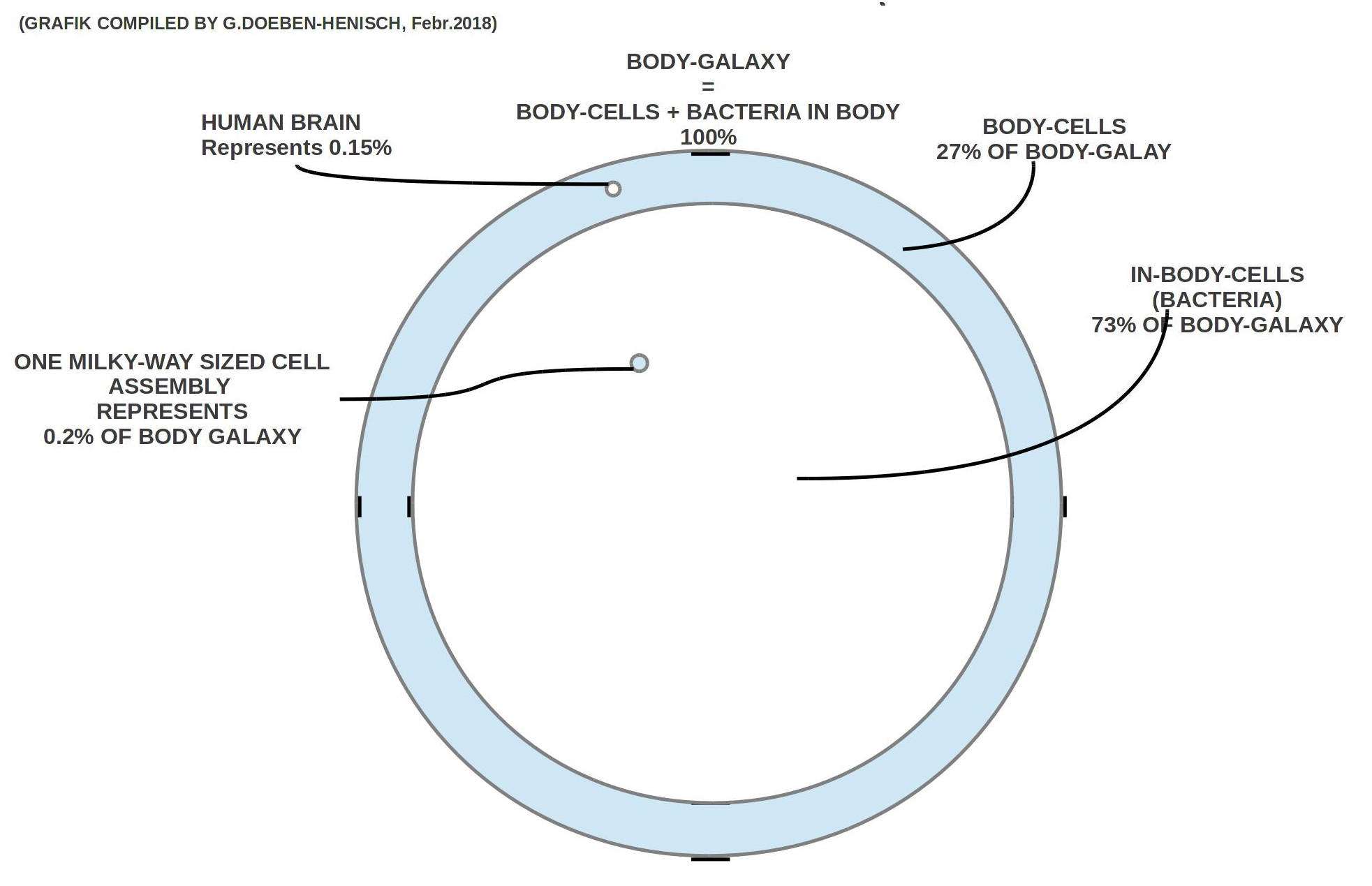
1) Die Körperzellen zusammen mit den Bakterien im Körper werden hier ’Body-Galaxy’ genannt und diese repräsentiert 100% aller Zellen.
2) Im Rahmen der Body-Galaxy haben die körperinternen Bakterien einen Anteil von ca. 73%, d.h. ca. 3/4 der Body-Galaxy. Über diese Bakterienpopulationen weiß die Mikrobiologie bis heute noch nicht all zu viel.
3) Alle Gehirnzellen machen in dieser Body-Galaxy etwa 0.15% aller Zellen aus.
4) Eine Galaxie vom Format der Milchstraße entspricht 0.2% der Zellen der Body-Galaxy und passt ca. 457 Mal in eine Body-Galaxy.
IV. PHILOSOPHISCHE ANMERKUNGEN
Die eben angeführte Zahlen und quantitativen Verhältnisse stehen erst einmal für sich. Insofern der homo sapiens, wir, nicht nur die Objekte der Betrachtung sind, sondern zugleich auch die Betrachter, jene, die die Wirklichkeit einschließlich unserer selbst beobachten und dann ’denken’ können, erlaubt unsere Denkfähigkeit uns, diese
Sachverhalte in alle möglichen Denkzusammenhänge einzubringen und mit ihnen ’zu spielen’. Von den unendlich vielen Aspekten, die man hier jetzt durchspielen könnte, im folgen drei.
A. Zusammenhang durch Funktionen
Aus Sicht der Zellen bildet ein menschlicher Körper eine Super-Galaxie unvorstellbaren Ausmaßes. Die Tatsache, dass eine einzelne Zelle ’autonom’ ist, in ihrem Verhalten nur sich selbst verpflichtet ist, eine einzelne Zelle von all den anderen Zellen auch nichts ’weiß’, dies wirft um so mehr die Frage auf, wie denn solch eine Super-Galaxie
von Zellen überhaupt funktionieren kann?
Durch die Mikrobiologie wissen wir heute, dass eine einzelne komplexe Zelle (d.h. eine ’eukaryotische Zelle’) selbst schon eine komplexe Struktur mit vielen zellähnlichen Unterstrukturen ist, in der sich Millionen von unterschiedlich komplexen Molekülen befinden, die miteinander interagieren; ebenso finden komplexe Interaktionen der Zelle mit ihrer Umgebung statt. Diese Interaktionen realisieren sich über molekulare Strukturen oder elektrische Potentiale (Die elektrischen Potentiale bilden sich durch Ionen, deren Elektronenverteilung ein negativ oder positiv geladenes elektrisches Feld erzeugt. Viele solcher Ionen können dann elektrische Potentiale erzeugen, die ’Wirkungen’ erzielen können, die man messen kann.)
Aus Sicht der Mathematik kann man diese Interaktionen als ’Funktionen’ beschreiben, in denen eine ’Region’ mittels molekularer Strukturen oder elektrischer Felder in einer anderen ’Region’ eine ’Veränderung’ bewirkt. Eine einzelne Zelle realisiert simultan viele tausende (Eine genaue Zahl kenne ich (noch) nicht.) solcher Funktionen. Die Mikrobiologie weiß heute auch schon, dass solche Interaktionen nicht nur zwischen einzelnen Zellen (also von A nach B und zurück) stattfinden, sondern dass es große Zellverbände sein können, die mit anderen Zellverbänden interagieren (man denke an ’Herz’, ’Lunge’, ’Gehirn’ usw.). Allerdings setzen diese ’Makro-Funktionen’ die vielen einzelnen Funktionen dabei voraus.
Wenn z.B. ein Auge mit seinen ca. 1 Millionen Rezeptoren Energieereignisse aus der Umgebung registrieren und in neuronale Signale ’übersetzen’ kann, dann geschieht dies zunächst mal in 1 Million Signalereignisse unabhängig voneinander, parallel, simultan. Erst durch die ’Verschaltung’ dieser Einzelereignisse entstehen daraus
Ereignisse, in denen viele einzelne Ereignisse ’integriert’/ ’repräsentiert’ sind, die wiederum viele unterschiedliche Erregungsereignisse nach sich ziehen. Würde man immer nur die ’lokalen Funktionen’ betrachten, dann würde man nicht erkennen können, dass alle diese lokalen Ereignisse zusammen nach vielen Interaktionsstufen zu einem
Gesamtereignis führen, das wir subjektiv als ’Sehen’ bezeichnen. Will man sinnvoll über ’Sehen’ sprechen, dann muss man gedanklich alle diese lokalen Funktionen ’begreifen’ als ’Teilfunktionen’ einer ’Makro-Funktion’, in der sich erst ’erschließt’, ’wofür’ alle diese lokalen Funktionen ’gut’ sind.
In der Erforschung des menschlichen Körpers hinsichtlich seiner vielen lokalen und immer komplexeren Makro-Funktionen steht die Wissenschaft noch ziemlich am Anfang. Aber, wenn man sieht, wie schwer sich die Physik mit den vergleichsweise ’einfachen’ ’normalen’ Galaxien tut, dann sollten wir uns nicht wundern, dass die vielen Disziplinen, die sich mit den Super-Galaxien biologischer Körper beschäftigen, da noch etwas Zeit brauchen.
B. Gehirn so winzig
Im Laufe der letzten 100 und mehr Jahre hat die Einsicht in die Bedeutung des Gehirns zugenommen. Bisweilen kann man den Eindruck haben, als ob es nur noch um das Gehirn geht. Macht man sich aber klar, dass das Gehirn nur etwa 0.15% der Körper-Galaxie ausmacht, dann darf man sich wohl fragen, ob diese Gewichtung
angemessen ist. So komplex und fantastisch das Gehirn auch sein mag, rein objektiv kann es nur einen Bruchteil der Körperaktivitäten ’erfassen’ bzw. ’steuern’.
Durch die Mikrobiologie wissen wir schon jetzt, wie Körperzellen und vor allem Bakterien, über chemische Botenstoffe das Gehirn massiv beeinflussen können. Besonders krasse Fälle sind jene, in denen ein Parasit einen Wirtsorganismus chemisch so beeinflussen kann, dass das Gehirn Handlungen einleitet, die dazu führen, dass der Wirtsorganismus zur Beute für andere Organismen wird, in denen der Parasit leben will. (Siehe dazu verschiedene Beispiel im Buch von Kegel (2015) [Keg15]:SS.282ff) Andere Beispiele sind Drogen, Nahrungsmittel, Luftbestandteile, die die Arbeitsweise des Gehirns beeinflussen, oder bestimmte Verhaltensweisen oder einen ganzen Lebensstil. Die Kooperation zwischen Gehirnforschung und anderen Disziplinen
(z.B. moderne Psychotherapie) nimmt glücklicherweise zu.
C. Bewusstsein: Was ist das?
Wenn man sieht, wie winzig das Gehirn im Gesamt der Körper-Galaxie erscheint, wird das Phänomen des ’Bewusstseins’ — das wir im Gehirn verorten — noch erstaunlicher, als es sowieso schon ist.
Schon heute wissen wir, dass diejenigen Erlebnisse, die unser Bewusstsein ausfüllen können, nur einen Bruchteil dessen abbilden, was das Gehirn als Ganzes registrieren und bewirken kann. Das – hoffentlich – unverfänglichste Beispiel ist unser ’Gedächtnis’.
Aktuell, in der jeweiligen Gegenwart, haben wir keine direkte Einsicht in die Inhalte unseres Gedächtnisses. Aufgrund von aktuellen Erlebnissen und Denkprozessen, können wir zwar – scheinbar ’mühelos’ – die potentiellen Inhalte ’aktivieren’, ’aufrufen’, ’erinnern’, verfügbar machen’, aber immer nur aktuell getriggert. Bevor mich jemand nach dem Namen meiner Schwestern fragt, werde ich nicht daran denken, oder meine Telefonnummer, oder wo ich vor zwei Monaten war, oder …. Wenn es aber ein Ereignis gibt, das irgendwie im Zusammenhang mit solch einem potentiellen Gedächtnisinhalt steht, dann kann es passieren, dass ich mich ’erinnere’, aber nicht notwendigerweise. Jeder erlebt ständig auch, dass bestimmtes Wissen nicht ’kommt’; besonders unangenehm in Prüfungen, in schwierigen Verhandlungen, in direkten Gesprächen.
Es stellt sich dann die Frage, wofür ist ein ’Bewusstsein’ gut, das so beschränkt und unzuverlässig die ’Gesamtlage’ repräsentiert?
Und dann gibt es da ein richtiges ’Bewusstseins-Paradox’: während die Ereignisse im Gehirn sich physikalisch-chemisch beschreiben lassen als Stoffwechselprozesse oder als elektrische Potentiale, die entstehen und vergehen, hat der einzelne Mensch in seinem Bewusstsein subjektive Erlebnisse, die wir mit ’Farben’ beschreiben können, ’Formen’, ’Gerüchen’, ’Klängen’ usw. Die Philosophen sprechen hier gerne von ’Qualia’ oder einfach von ’Phänomenen’. Diese Worte sind aber ziemlich beliebig; sie erklären nichts. Das Paradox liegt darin, dass auf der Ebene der Neuronen Ereignisse, die visuelle Ereignisse repräsentieren oder akustische oder olfaktorische usw.
physikalisch-chemisch genau gleich beschaffen sind. Aus dem Messen der neuronalen Signale alleine könnte man nicht herleiten, ob es sich um visuelle, akustische usw. Phänomene im Kontext eines Bewusstseins handelt. Subjektiv erleben wir aber unterschiedliche Qualitäten so, dass wir mittels Sprache darauf Bezug nehmen können.
Ein eigentümliches Phänomen.
Ein anderes Paradox ist der sogenannte ’freie Wille’. Die Vorstellung, dass wir einen ’freien Willen’ haben, mit dem wir unser Verhalten autonom bestimmten können, ist im kulturellen Wissen tief verankert. Bedenkt man die prekäre Rolle des Gehirns in der Körper-Galaxie, dazu die Beschränkung des Bewusstseins auf nur Teile der Gehirnereignisse, dann tut man sich schwer mit der Vorstellung, dass der einzelne Mensch über sein Bewusstsein irgendwie ’substantiell’ Einfluss auf das Geschehen seiner Körper-Galaxie nehmen kann.
Gerade die Gehirnforschung konnte uns immer mehr Beispiele bringen, wie eine Vielzahl von chemischen Botenstoffen über das Blut direkten Einfluss auf das Gehirn nehmen kann. Zusätzlich hatte schon viel früher die Psychologie (und Psychoanalyse?) an vielen Beispielen verdeutlichen können, dass wir Menschen durch falsche Wahrnehmung, durch falsche Erinnerungen und durch falsche gedanklichen Überlegungen, durch Triebe, Bedürfnisse, Emotionen und Gefühle unterschiedlichster Art das ’Falsche’ tun können.
Alle diese Faktoren können offensichtlich unsere unterstellte Freiheit beeinflussen und erschweren, können sie sie aber grundsätzlich aufheben?
Es gibt zahllose Beispiele von Menschen, die trotz vielfältigster körperlicher, psychischer und sozialer Erschwernisse Dinge getan haben, die die scheinbare Unausweichlichkeit solcher unterstellter Kausalitäten individuell unterbrochen und aufgehoben haben und zu Handlungen und Lebensverläufen gekommen sind, die
man als Indizien dafür nehmen kann, dass der Komplex ’Bewusstsein’ und ’freier Wille’ eventuell noch mehr überraschende Eigenschaften besitzt, als sie in der aktuellen – eher mechanistischen – Betrachtungsweise sichtbar werden.
Der Autor dieser Zeilen geht davon aus, dass es sogar ziemlich sicher solche weiteren Aspekte gibt, die bislang nur deshalb noch nicht Eingang in die Diskussion gefunden haben, weil die Theoriebildung im Bereich der Super-Galaxien der Körper und dann noch umfassender der gesamten biologischen Evolution noch nicht allzu weit
fortgeschritten ist. Sie steht noch ziemlich am Anfang.
V. ANHANG : RECHENVORSCHRIFTEN
Für die einfachen Rechnungen habe ich die Sprache python (Siehe Rossum (2017) [RPDT17]) in Version 3.5.2 benutzt.
# hscomplex.py
# author: Gerd Doeben-Henisch
# idea: comparing the complexity of humans (homo sapiens, hs) with the milky way galaxy
# See paper: cognitiveagent.org, February-18, 2018
#######################
# IMPORT MODULES
########################
import math
#########################
# GLOBAL VALUES
##########################
bodycells = 37200000000000
inbodycells = 100000000000000
milkyway = 300000000000
bodygalaxy=bodycells+inbodycells
gliacells = 100000000000
ratioglianeuron = 1/1
neurons = gliacells *ratioglianeuron
braincells = neurons + gliacells
#########################
# CALCULATIONS
##########################
bodygalaxymilkywayunits=bodygalaxy/milkyway
print(’Number of Milky Way Objects possible within Body-Galaxy =’,bodygalaxymilkywayunits)
percentmilkywaybody=milkyway/(bodygalaxy/100)
print(’Percentage of Milky Way object within Body-Galaxy =’,percentmilkywaybody)
percentbrainbody=braincells/(bodygalaxy/100)
print(’Percentage of Brain object within Body-Galaxy =’, percentbrainbody)
percentbodybact=bodycells/(bodygalaxy/100)
print(’Percentage of body cells within body-galaxy =’,percentbodybact)
radiusinbody=math.sqrt((inbodycells/math.pi)*4)/2
radiusmilkyway=math.sqrt((milkyway/math.pi)*4)/2
radiusbodygalaxy=math.sqrt((bodygalaxy/math.pi)*4)/2
radiusinbodybodygalaxy=radiusinbody/radiusbodygalaxy
print(’Proportion of radius inbody cells to radius body galaxy =’,radiusinbodybodygalaxy)
radiusmilkywaybodygalaxy=radiusmilkyway/radiusbodygalaxy
print(’Proportion of radius milky way to radius body galaxy =’, radiusmilkywaybodygalaxy)
radiusbrain=math.sqrt((braincells/math.pi)*4)/2
radiusbraincellsbodygalaxy=radiusbrain/radiusbodygalaxy
print(’Proportion of radius brain to radius body galaxy =’, radiusbraincellsbodygalaxy)
VI. ANHANG : AUSFÜHRUNG VON RECHENVORSCHRIFTEN
(eml) gerd@Doeben-Henisch: ̃/environments/eml/nat$ python hscomplex.py
Number of Milky Way Objects possible within Body-Galaxy = 457.3333333333333
Percentage of Milky Way object within Body-Galaxy = 0.21865889212827988
Percentage of Brain object within Body-Galaxy = 0.1457725947521866
Percentage of body cells within body-galaxy = 27.113702623906704
Proportion of radius inbody cells to radius body galaxy = 0.8537347209531384
Proportion of radius milky way to radius body galaxy = 0.04676097647914122
Proportion of radius brain to radius body galaxy = 0.038180177416060626
QUELLEN
[AJL + 15] B. Alberts, A. Johnson, J. Lewis, D. Morgan, M. Raff, K. Roberts, and P. Walter. Molecular Biology of the Cell. Garland Science,
Taylor & Francis Group, LLC, Abington (UK) – New York, 6 edition, 2015.
[BS06] Niels Birbaumer and Robert F. Schmidt. Biologische Psychologie. Springer, Heidelberg, 6 edition, 2006.
[Keg15] Bernhard Kegel. Die Herrscher der Welt. DuMont, Köln (DE), 1 edition, 2015.
[Mas15] Maggie Masetti. How many stars in the milky way? blueshift, 2015. https://asd.gsfc.nasa.gov/blueshift/index.php/2015/07/22/how-
many-stars-in-the-milky-way.
[RPDT17] Guido van Rossum and Python-Development-Team. The Python Language Reference, Release 3.6.3. Python Software Foundation,
Email: docs@python.org, 1 edition, 2017. https://docs.python.org/3/download.html.
[vBBHH16] Christopher S. von Bartheld, Jami Bahney, and Suzana Herculano-Houzel. The search for true numbers of neurons and glial cells
in the human brain: A review of 150 years of cell counting. Journal of Comparative Neurology, 524(18):3865–3895, 2016.
KONTEXT BLOG
Einen Überblick über alle Blogeinträge von Autor cagent nach Titeln findet sich HIER.
Einen Überblick über alle Themenbereiche des Blogs findet sich HIER.
Das aktuelle Publikationsinteresse des Blogs findet sich HIER

