Zeit: 8.Febr 24 – 3.März 24
Autor: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
KONTEXT
Das Thema Mensch und Maschine durchzieht den gesamten Blog von Anfang an. Es liegt daher nahe, diese Thematik auch in Vorträgen zu thematisieren. Allerdings, jede der beiden Komponenten ‚Mensch‘ wie auch ‚Maschine‘ ist in sich sehr komplex; eine Wechselwirkung zwischen beiden umso mehr. Dazu ‚einfach mal so‘ einen Vortrag zu halten erscheint daher fast unmöglich, wie eine ‚Quadratur des Kreises‘. Dennoch lasse ich mich gelegentlich darauf ein.
Überblick
Im Teil 1 wird eine Ausgangslage beschrieben, die in Vorbereitung eines Vortrags angenommen worden ist. Im Rahmen des Vortrags konnte das Thema aber nur ansatzweise behandelt werden. In den nachfolgenden Texten soll die Themenstellung daher nochmals aufgegriffen und ausführlicher behandelt werden.
Ankündigung des Vortrags
Im offiziellen Ankündigungs-Flyer konnte man folgenden Text lesen:
Perspektive Vortragender
Das Eigentümliche von freien Vorträgen ist, dass man die Zusammensetzung des Publikums vorab nicht kennt. Man muss mit einer großen Vielfalt rechnen, was auch am 21.Febr 2024 der Fall war. Ein voller Saal, immerhin fast alle hatten schon mal Kontakt mit chatGPT gehabt, manche sogar sehr viel Kontakt. Wie ein roter Faden liefen aber bei allen Fragen der Art mit, was man denn jetzt von dieser Software halten solle? Ist sie wirklich intelligent? Kann sie eine Gefahr für uns Menschen darstellen? Wie soll man damit umgehen, dass auch immer mehr Kinder und Jugendliche diese SW benutzen ohne wirklich zu verstehen, wie diese SW arbeitet? … und weitere Fragen.
Als Vortragender kann man auf die Vielzahl der einzelnen Fragen kaum angemessen eingehen. Mein Ziel war es, ein Grundverständnis von der Arbeitsweise von chatGPT4 als Beispiel für einen chatbot und für generative KI zu vermitteln, und dieses Grundverständnis dann in Bezug zu setzen, wie wir Menschen mit dem Problem Zukunft umgehen: auf welche Weise kann chatGPT4 uns helfen, Zukunft gemeinsam ein wenig zu verstehen, so dass wir dadurch gemeinsam etwas rationaler und zielgerichteter handeln können.
Ob und wieweit mir dies dann faktisch im Vortrag und bei den Gesprächen gelungen ist, bleibt eine offene Frage. Bei einigen, die aufgrund ihrer individuellen Experimente mit chatGPT sich schon ein bestimmtes Bild von chatGPT gemacht hatten, sicher nicht. Sie waren so begeistert davon, was chatGPT alles kann, dass sie weiterführende Überlegungen eher abwehrten.
Absicht des Vortragenden
Wie schon angedeutet, gab es die Themenkomplexe (i) chatbots/ generative KI/ KI, (ii) Zukunft verstehen und gestalten sowie (iii) Ob und wie kann generative KI uns Menschen dabei helfen.
Chatbots/ Generative KI/ KI
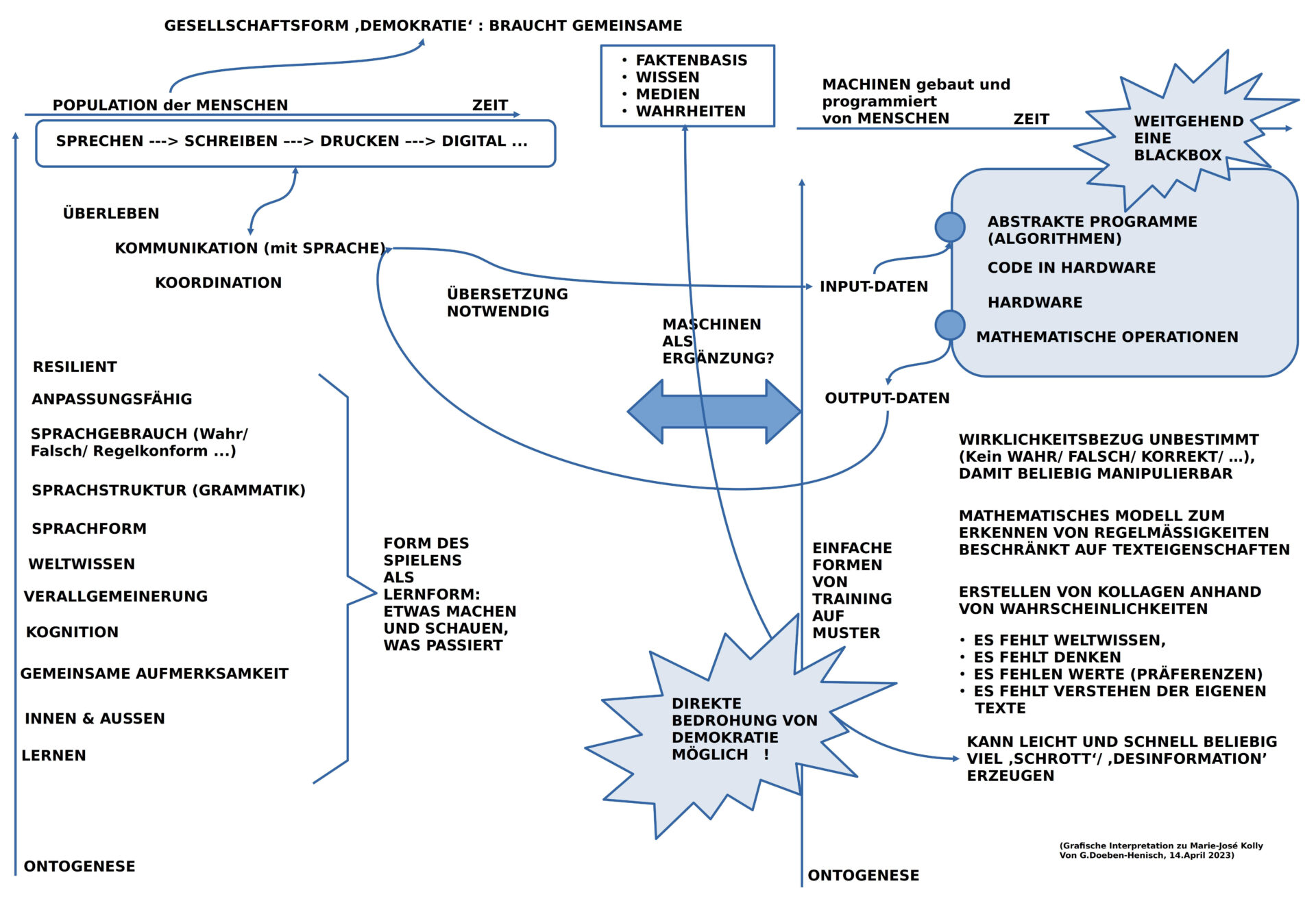
Aufgrund der heute stark ausgefächerten Terminologie mit stark verschwommenen Bedeutungsrändern habe ich eine Skizze des Begriffsfelds in den Raum gestellt, um dann Eliza und chatGPT4 als Beispiel für chatbots/ generative KI/ maschinelles Lernen näher zu betrachten.
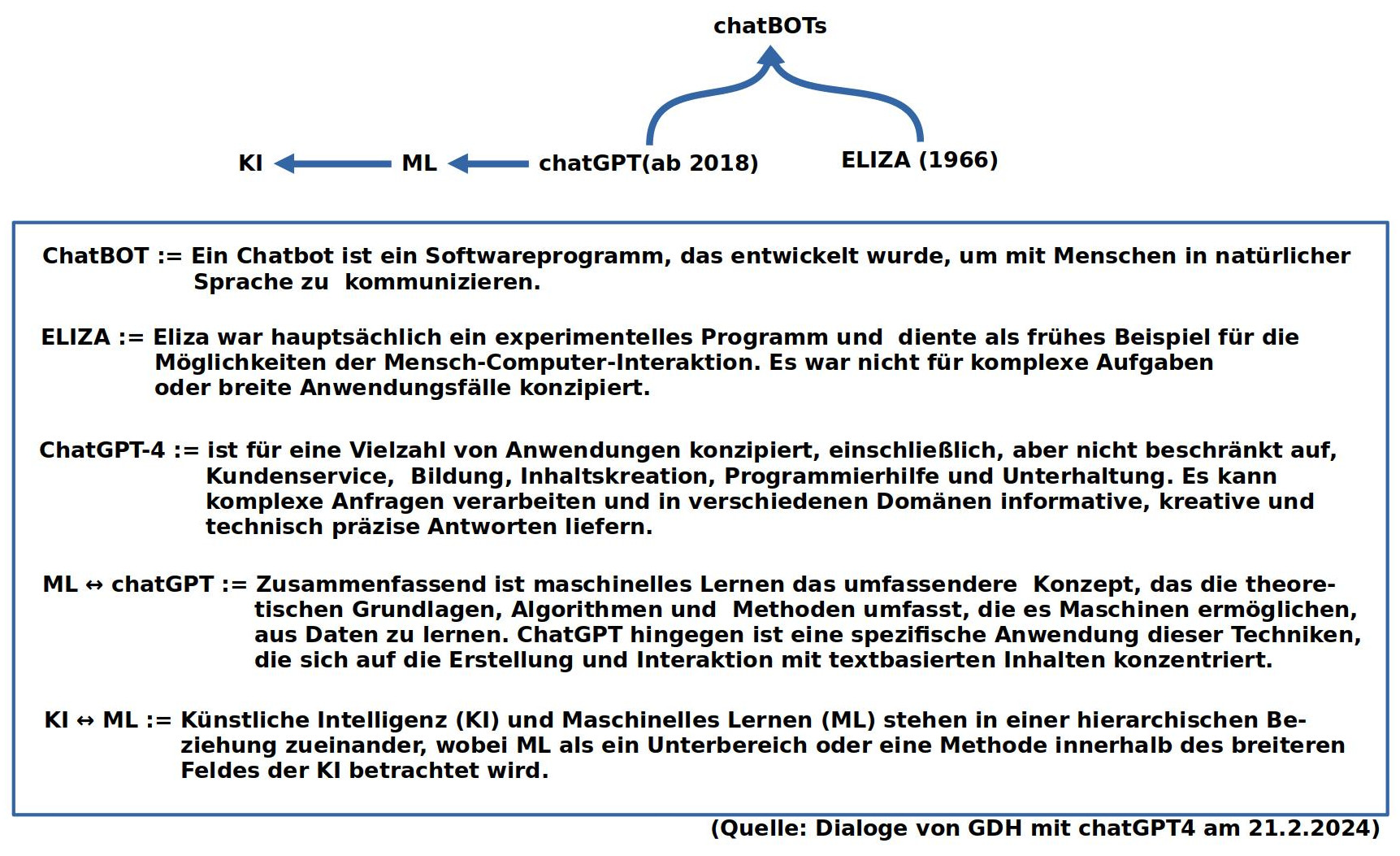
Das Programm Eliza [1,2] ist insoweit von historischem Interesse, als es der erste chatbot [3] war, der einige Berühmtheit erlangte. Trotz seiner einfachen Struktur (ohne jede explizite Wissensbasis) übte der chatbot eine starke Wirkung auf die Menschen aus, die mit dem Programm per Tastatur und Bildschirm interagierten. Alle hatten das Gefühl, dass der chatbot sie ‚versteht‘. Dies verweist auf Grundmuster der menschlichen Psychologie, Vertrauen zu schenken, wenn erlebte Interaktionsformen den persönlichen Erwartungen entsprechen.
Verglichen mit Eliza besitzt der chatbot chatGPT4 [4a,b,c] eine unfassbar große Datenbasis von vielen Millionen Dokumenten, sehr breit gestreut. Diese wurden miteinander ‚verrechnet‘ mit Blick auf mögliche Kontexte von Worten samt Häufigkeiten. Zusätzlich werden diese ‚Sekundärdaten‘ in speziellen Trainingsrunden an häufig vorkommende Dialogformen angepasst.
Während Eliza 1966 nur im Format eines Psychotherapeuten im Stil der Schule von Rogers [5] antworten konnte, weil das Programm speziell dafür programmiert war, kann chatGPT4 ab 2023 viele verschiedene Therapie-Formen nachahmen. Überhaupt ist die Bandbreite möglicher Interaktionsformen von chatGPT4 erheblich breiter. So kann man folgenden Formate finden und ausprobieren:
- Fragen beantworten …
- Texte zusammenfassen …
- Texte kommentieren …
- Texte entwerfen …
- Übersetzen …
- Text zu Bild …
- Text zu Video
- … und weitere …
Bewertung
Eine Software wie chatGBT4 zu benutzen ist das eine. Wie aber kann man solch eine Software bewerten?
Aus dem Alltag wissen wir, dass wir zur Feststellung der Länge eines bestimmten räumlichen Abschnitts ein standardisiertes Längenmaß wie ‚das Meter‘ benutzen oder für das Gewicht eines Objekts das standardisierte Gewichtsmaß ‚das Kilogramm‘.[6]
Wo gibt es eine standardisierte Maßeinheit für chatbots?
Je nachdem, für welche Eigenschaft man sich interessiert, kann man sich viele Maßeinheiten denken.
Im hier zur Debatte stehenden Fall soll es um das Verhalten von Menschen gehen, die gemeinsam mittels Sprache sich auf die Beschreibung eines möglichen Zustands in der Zukunft einigen wollen, so, dass die einzelnen Schritte in Richtung Ziel überprüfbar sind. Zusätzlich kann man sich viele Erweiterungen denken wie z.B. ‚Wie viel Zeit‘ wird die Erreichung des Ziels benötigen?‘, ‚Welche Ressourcen werden benötigt werden zu welchen Kosten?‘, ‚Wie viele Menschen mit welchen Fähigkeiten und in welchem zeitlichem Umfang müssen mitwirken? … und einiges mehr.
Man merkt sofort, dass es hier um einen ziemlich komplexen Prozess geht.
Um diesen Prozess wirklich als ‚Bezugspunkt‘ wählen zu können, der in seinen einzelnen Eigenschaften dann auch ‚entscheidbar‘ ist hinsichtlich der Frage, ob chatGPT4 in diesem Kontext hilfreich sein kann, muss man diesen Prozess offensichtlich so beschreiben, dass ihn jeder nachvollziehen kann. Dass man dies tun kann ist keineswegs selbstverständlich.
Anforderungen für eine gemeinsame Zukunftsbewältigung
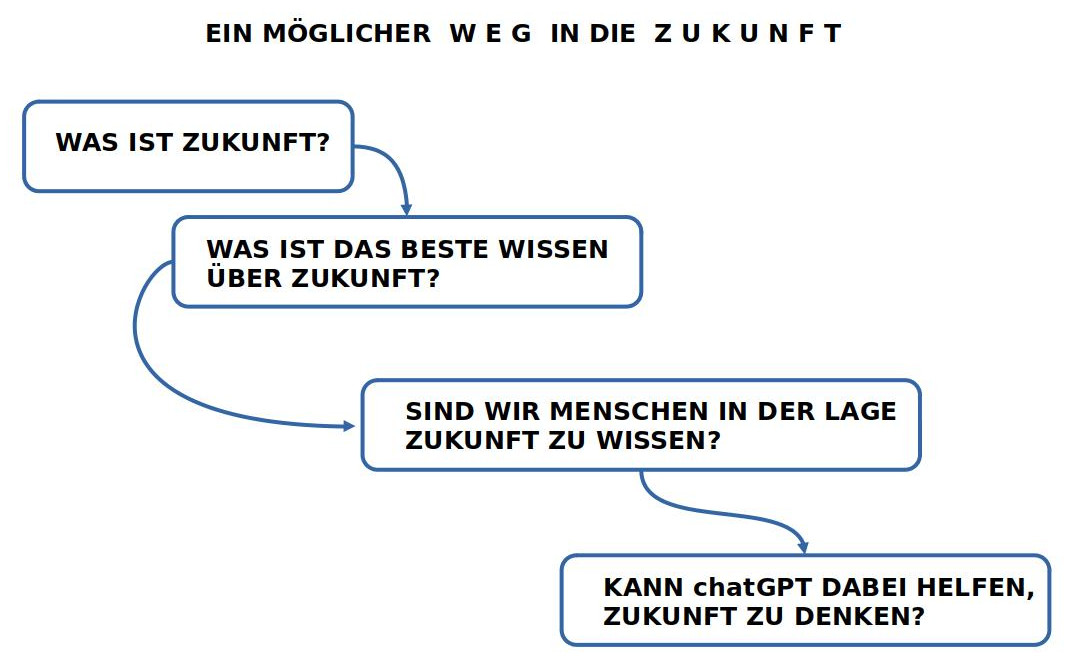
BILD : Andeutung der Fragen, die beantwortet werden müssen, um möglicherweise eine Antwort zu bekommen.
ZUKUNFT KEIN NORMALES OBJEKT
Generell gilt, dass das mit dem Wort ‚Zukunft‘ Gemeinte kein normales Objekt ist wie ein Stuhl, ein Auto, oder ein Hund, der gerade über die Straße läuft. Zukunft kommt für uns immer nur in unserem Denken vor als Bild eines möglichen Zustands, das sich nach einer gewissen Zeit möglicherweise ‚bewahrheiten kann‘.
Wollen wir also möglichst viele Menschen in die Zukunft mitnehmen, dann stellt sich die Aufgabe, dass das gemeinsamen Denken möglichst viel von dem, was wir uns für die Zukunft wünschen, ‚voraus sehen‘ können muss, um einen Weg in ein mögliches gedachtes Weiterleben zu sichern.
BEISPIEL MIT BRETTSPIEL
Dies klingt kompliziert, aber anhand eines bekannten Brettspiels kann man dies veranschaulichen. Auf Deutsch heißt dies Spiel ‚Mensch ärgere Dich nicht‘ (auf dem Bild sieht man eine Version für die Niederlande).[7]

BILD : Spielbrett des Spiels ‚Mensch ärgere Dich nicht‘
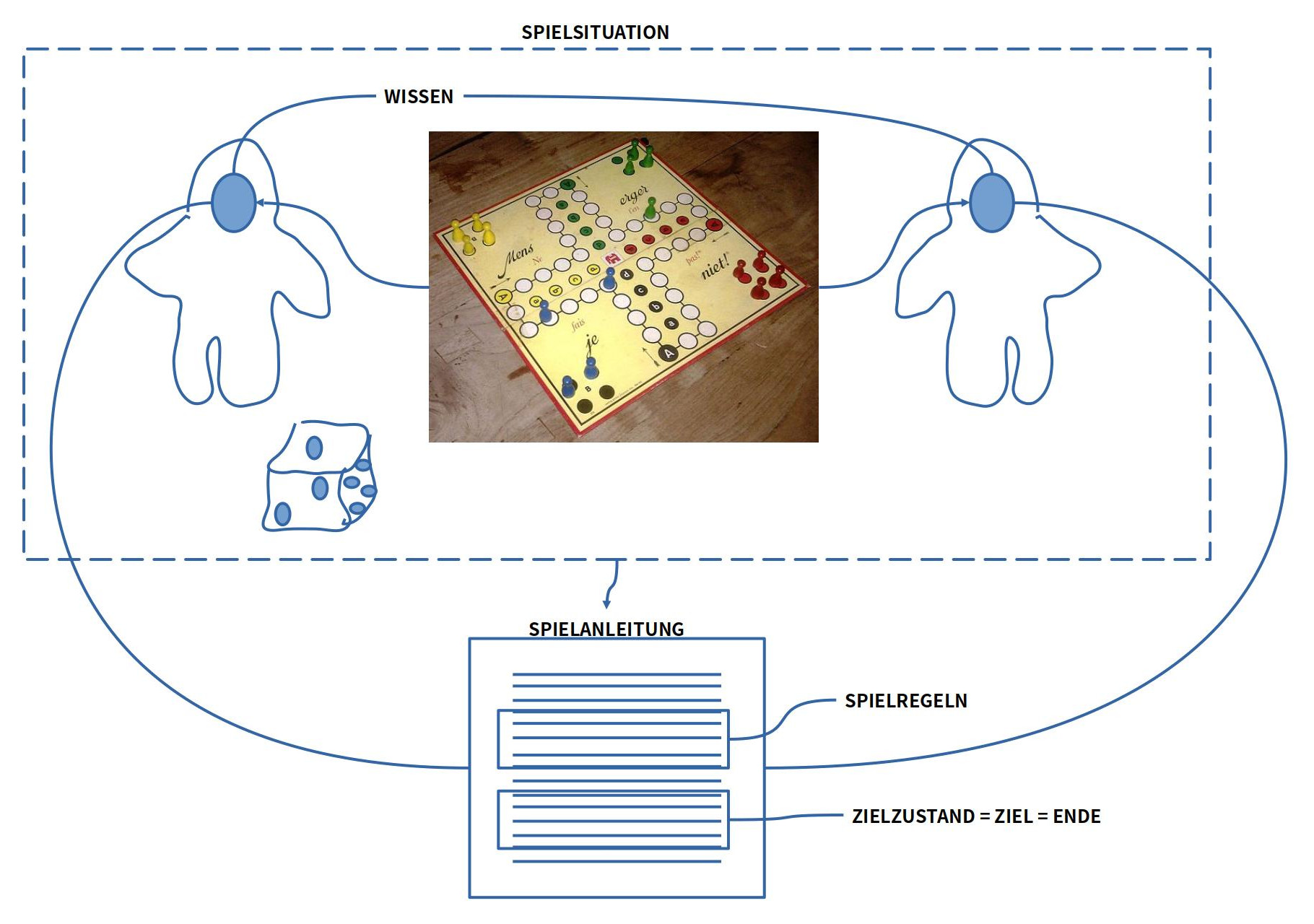
BILD : Strukturelemente einer Spielsituation und die darin angenommenen Beziehungen. Die reale SPIELSITUATION wird im Text der SPIELANLEITUNG vorausgesetzt und beschrieben. Neben den ELEMENTEN der Spielsituation enthalten die SPIELREGELN Beschreibungen möglicher Aktionen, um die Spielsituation zu verändern sowie die Beschreibung einer möglichen Konfiguration von Elementen, die (i) als STARTSITUATION gelten soll wie auch als ZIELZUSTAND (ZIEL). Ferner gibt es eine ANLEITUNG, WER WAS WANN WIE tun darf.
Was man in der Gegenwart sieht, das ist ein Spielbrett mit diversen Symbolen und Spielsteinen. Zusätzlich gibt es noch den Kontext zum Spielbrett bestehend aus vier Spielern und einem Würfel. Alle diese Elemente zusammen bilden eine Ausgangslage oder Startzustand oder den aktuellen IST-Zustand.
Ferner muss man annehmen, dass sich in den Köpfen der Mitspieler ein Wissen befindet, aufgrund dessen die Mitspieler die einzelnen Elemente als Elemente eines Spiels erkennen können, das ‚Mensch ärgere dich nicht‘ heißt.
Um dieses Spiel praktisch spielen zu können, müssen die Spieler auch wissen, wer wann welche Veränderungen wie auf dem Spielbrett vornehmen darf. Diese Veränderungen werden beschrieben durch Spielregeln, zu denen es noch eine geschriebene Spielanleitung gibt, aus der hervorgehen muss, welche Regel wann wie von wem angewendet werden darf.
Wenn die Spieler nach den vorgegebenen Regeln Veränderungen auf dem Spielbrett vornehmen, dann kann das Spiel beliebig lange laufen, es sei denn, es gibt eine klar Beschreibung eines Zielzustands, der als Ziel und gleichzeitig als Ende vereinbart ist. Wenn dieser Zielzustand auf dem Brett eintreten sollte, dann wäre das Spiel beendet und jener Spieler, der den Zielzustand als erster erreicht, wäre dann ein Gewinner im Sinne des Spiels.
Nicht zu vergessen: Genauso wichtig die die Beschreibung eines Zielzustandes ist die Beschreibung eines Startzustands, mit dem das Spiel beginnen soll.
Für die Frage der Zukunft im Kontext Spiel wird sichtbar, dass die Zukunft in Gestalt eines Zielzustands zwar in Form einer textlichen Beschreibung existiert, aber nicht als reale Konfiguration auf dem Spielbrett. Es wird von den beteiligten Spielern aber angenommen, dass die beschrieben Zielkonfiguration durch wiederholte Ausführung von Spielregeln beginnend mit einer Startkonfiguration irgendwann im Verlaufe des Spiels eintreten kann. Im Fall des Eintretens der Zielkonfiguration als reale Konfiguration auf dem Spielbrett wäre dies für alle wahrnehmbar und entscheidbar.
Interessant in diesem Zusammenhang ist der Sachverhalt, dass die Auswahl eines Zielzustands nur möglich ist, weil die Vorgabe einer Startsituation in Kombination mit Spielregeln einen Raum von möglichen Zuständen markiert. Der Zielzustand ist dann immer die Auswahl einer spezifischen Teilmenge aus dieser Menge der möglichen Folgezuständen.
Spiel und Alltag
Wenn man sich den Alltag anschaut, auch dort, wo nicht explizit ein Spiel gespielt wird, dann kann man feststellen, dass sehr viele — letztlich alle ? — Situationen sich als Spiel interpretieren lassen. Ob wir die Vorbereitung eines Essens nehmen, den Tisch decken, Zeitung lesen, Einkaufen, Musik machen, Auto fahren …. alle diese Tätigkeiten folgen dem Schema, dass es eine Ausgangssituation (Startsituation) gibt, ein bestimmtes Ziel, das wir erreichen wollen, und eine Menge von bestimmten Verhaltensweisen, die wir gewohnt sind auszuführen, wenn wir das spezielle Ziel erreichen wollen. Verhalten wir uns richtig, dann erreichen wir — normalerweise — das gewünschte Ziel. Diese Alltagsregeln für Alltagsziele lernt man gewöhnlich nicht in er Schule, sondern durch die Nachahmung anderer oder durch eigenes Ausprobieren. Durch die Vielfalt von Menschen und Alltagssituationen mit unterschiedlichsten Zielen gibt es eine ungeheure Bandbreite an solchen Alltags-Spielen. Letztlich erscheinen diese als die Grundform menschlichen Verhaltens. Es ist die Art und Weise, wie wir als Menschen lernen und miteinander handeln. [8]
Im Unterschied zu expliziten Spielen verlaufen die Alltagsspiele nicht starr innerhalb der von der Spielanleitung beschriebenen Grenzen, sondern die Alltagsspiele finden innerhalb einer offenen Welt statt, sie sind ein kleiner Teil eines größeren dynamischen Gesamtgeschehens, welches dazu führen kann, dass während der Umsetzung eines Alltagsspiels andere Ereignisse die Umsetzung auf unterschiedliche Weise behindern können (Ein Telefonanruf unterbricht, Zutaten beim Kochen fehlen, beim Einkaufen findet man nicht den richtigen Gegenstand, …). Außerdem können Ziele im Alltag auch scheitern und können neben schlechten Gefühlen real auch negative Wirkungen erzeugen. Auch können Alltagsspiele irgendwann unangemessen werden, wenn sich die umgebende dynamische Welt soweit geändert hat, dass ein die Regeln des Alltagsspiels nicht mehr zum erhofften Ziel führen.
Vor diesem Hintergrund kann man vielleicht verstehen, dass explizite Spiele eine besondere Bedeutung haben: sie sind keine Kuriositäten im Leben der Menschen, sondern sie repräsentieren die normalen Strukturen und Prozesse des Alltags in zugespitzten, kondensierten Formaten, die aber von jedem Menschen mehr oder weniger sofort verstanden werden bzw. verstanden werden können.[9] Die Nichterreichung eines Zieles im expliziten Spiel kann zwar auch schlechte Gefühle auslösen, hat aber normalerweise keine weiteren reale negative Auswirkungen. Explizite Spiele ermöglichen es, ein Stück weit reale Welt zu spielen ohne sich dabei aber einem realen Risiko auszusetzen. Diese Eigenschaft kann für Mitbürger eine große Chance auch für den realen Alltag bieten.
Wissen und Bedeutung oder: Der Elefant im Raum
Ist man erst einmal aufmerksam geworden auf die Allgegenwart von Spielstrukturen in unserem Alltag, dann erscheint es fast ’normal‘, dass wir Menschen uns im Format des Spiels scheinbar schwerelos bewegen können. Wo immer man hinkommt, wen man auch immer trifft, das Verhalten im Format eines Spiels ist jedem vertraut. Daher fällt es meistens gar nicht auf, dass hinter dieser Verhaltensoberfläche einige Fähigkeiten des Menschen aktiv sind, die als solche alles andere als selbstverständlich sind.
Überall dort, wo mehr als ein Mensch sich im Format eines Spiels verhält, müssen alle beteiligten Menschen (Mitspieler, Mitbürger,…) in ihrem Kopf über ein Wissen verfügen, in dem alle Aspekte, die zu einem spielerischen Verhalten gehören, vorhanden (repräsentiert) sind. Wenn ein Spieler beim Fußballspiel nicht weiß, wann er im Abseits steht, macht er einen Fehler. Wer nicht weiß, dass man beim Einkaufen am Ende seine Waren bezahlen muss, macht einen Fehler. Wer nicht weiß, wie man bei der Essenszubereitung richtig schneidet/ würzt/ brät/ … verändert dies das erhoffte Ergebnis. Wer nicht weiß, wie er Bargeld aus dem Automat bekommt, hat ein Problem … Jeder lernt im Alltag, dass er wissen muss, um richtig handeln zu können. Was aber hat es genau mit diesem Wissen auf sich?
Und, um die Geschichte vollständig zu erzählen: Im Alltag operieren wir ständig mit Alltagssprache: wir produzieren Laute, die andere hören können und umgekehrt. Das Besondere an diesen Lauten ist, dass alle Teilnehmer des Alltags die eine gleiche Alltagssprache gelernt haben, diese Laute spontan in ihrem Kopf mit Teilen des Wissens verknüpfen, über das sie verfügen. Die gesprochenen und gehörten Laute sind daher nur ein Mittel zum Zweck. Als solche haben die Laute keine Bedeutung (was man sofort merken kann, wenn jemand die benutzte Alltagssprache nicht kennt). Aber für die, die die gleiche Alltagssprache im Alltag gelernt haben, stimulieren diese Laute in ihrem Kopf bestimmte Wissenselemente, falls wir über sie verfügen. Solche Wissenselemente, die sich durch die Laute einer gelernten Alltagssprache in einem Mitbürger stimulieren lassen, nennt man gewöhnlich sprachliche Bedeutung, wobei hier nicht nur die gehörten Laute alleine eine Rolle spielen, sondern normalerweise sind viele Kontexteigenschaften zusätzlich wichtig: Wie jemand etwas sagt, unter welchen Begleitumständen, in welcher Rolle usw. Meist muss man in der Situation des Sprechens anwesend sein, um all diese Kontextfaktoren erfassen zu können.
Hat man verstanden, dass jede geteilte Alltagssituation im Spielformat zentral zum notwendigen Alltagswissen auch eine Alltagssprache voraussetzt, dann wird auch klar, dass jedes explizite Spiel im Format einer Spielanleitung genau jenes Spielwissen bereit zu stellen versucht, welches man kennen muss, um das explizite Spiel spielen zu können. Im Alltag entsteht das notwendige Wissen durch Lernprozesse: durch Nachahmung und Ausprobieren baut jeder in seinem Kopf jenes Wissen auf, das er für ein bestimmtes Alltagshandeln benötigt. Für sich alleine braucht man nicht unbedingt einen Text, der das eigene Alltagshandeln beschreibt. Will man aber andere Mitbürger in sein Alltagsverhalten einbeziehen — gerade auch wenn es viele sein sollen, die nicht unbedingt am gleichen Ort sind –, dann muss man sein Alltagsverhalten mittels Alltagssprache ausdrücken.
Wissenschaftliches Denken und Kommunizieren
Für alle die, die nicht direkt mit wissenschaftlicher Arbeit zu tun haben, bildet Wissenschaft eine Zusammenballung von vielen unverständlichen Begriffen, Sprachen und Methoden. Dies führt in der Gegenwart leider vielfach zu einer Art Entfremdung der normalen Bürger von der Wissenschaft. Was nicht nur schade ist, sondern für eine Demokratie sogar gefährlich werden kann.[10,11]
Diese Entfremdung müsste aber nicht stattfinden. Die Alltagsspiele wie auch die expliziten Spiele, welche unsere natürlichen Wissens- und Verhaltensformen im Alltag darstellen, haben bei näherer Betrachtung die gleiche Struktur wie wissenschaftliche Theorien. Begreift man, dass Alltagsspiele strukturgleich mit wissenschaftlichen Theorien sind, dann kann man sogar entdecken, dass Alltagtheorien sogar noch umfassender sind als normale wissenschaftliche Theorien. Während eine empirisch Theorie (ET) erklären kann, was mit einer gewissen Wahrscheinlichkeit in einer möglichen nachfolgenden Situation passieren kann, falls gewisse Voraussetzungen in einer Situation gegeben sind, gehen Alltagstheorien über diese Beschreibungskraft in der Regel hinaus: In einer Alltagstheorie wird nicht nur gesagt, was passieren wird, wenn man in einer bestimmten Situation eine bestimmte Änderung vornimmt, sondern im Alltag wählt man normalerweise auch ein bestimmtes Ziel aus, das man mit Anwendung des Veränderungswissens erreichen möchte.
Im Unterschied zu einer normalen empirischen Theorie, die sich auf erklärende Zusammenhänge beschränkt, besteht im Alltagsprozess die beständige Herausforderung, den Lebensprozess des einzelnen wie jenen von unterschiedlichen Gruppen von Menschen bestmöglichst am Laufen zu halten. Dies aber geht nicht ohne explizite Ziele, deren Einlösung als Beitrag zur Erhaltung des alltäglichen Lebensprozesses angenommen wird.
Die normale Wissenschaft hat diesen Aspekt der Einbeziehung von Zielen in eine Theoriebildung noch nicht in ihre normale Arbeit integriert. Die Verknüpfung von Erklärungswissen in Form einer empirischen Theorie (ET) mit irgendwelchen Zielen überlässt die Wissenschaft bislang der Gesellschaft und ihren unterschiedlichen Gruppierungen und Institutionen. Dies kann gut sein, weil dadurch eine maximale Bandbreite an möglichen Ideen zur Sprache kommen kann; es kann aber auch schlecht sein, wenn mangels Verständnis von Wissenschaft und überhaupt aufgrund von mangelndem Wissen keine guten Ziel-Vorschläge zustande kommen.
Alltagstheorie (AT) und Empirische Theorie (ET)
Mancher wird sich an dieser Stelle vielleicht fragen, wie man sich jetzt genau die Struktur-Gleichheit von Alltagstheorien (AT) und Nachhaltigen Empirischen Theorien (NET) vorstellen kann. Hier ein kurze Beschreibung.
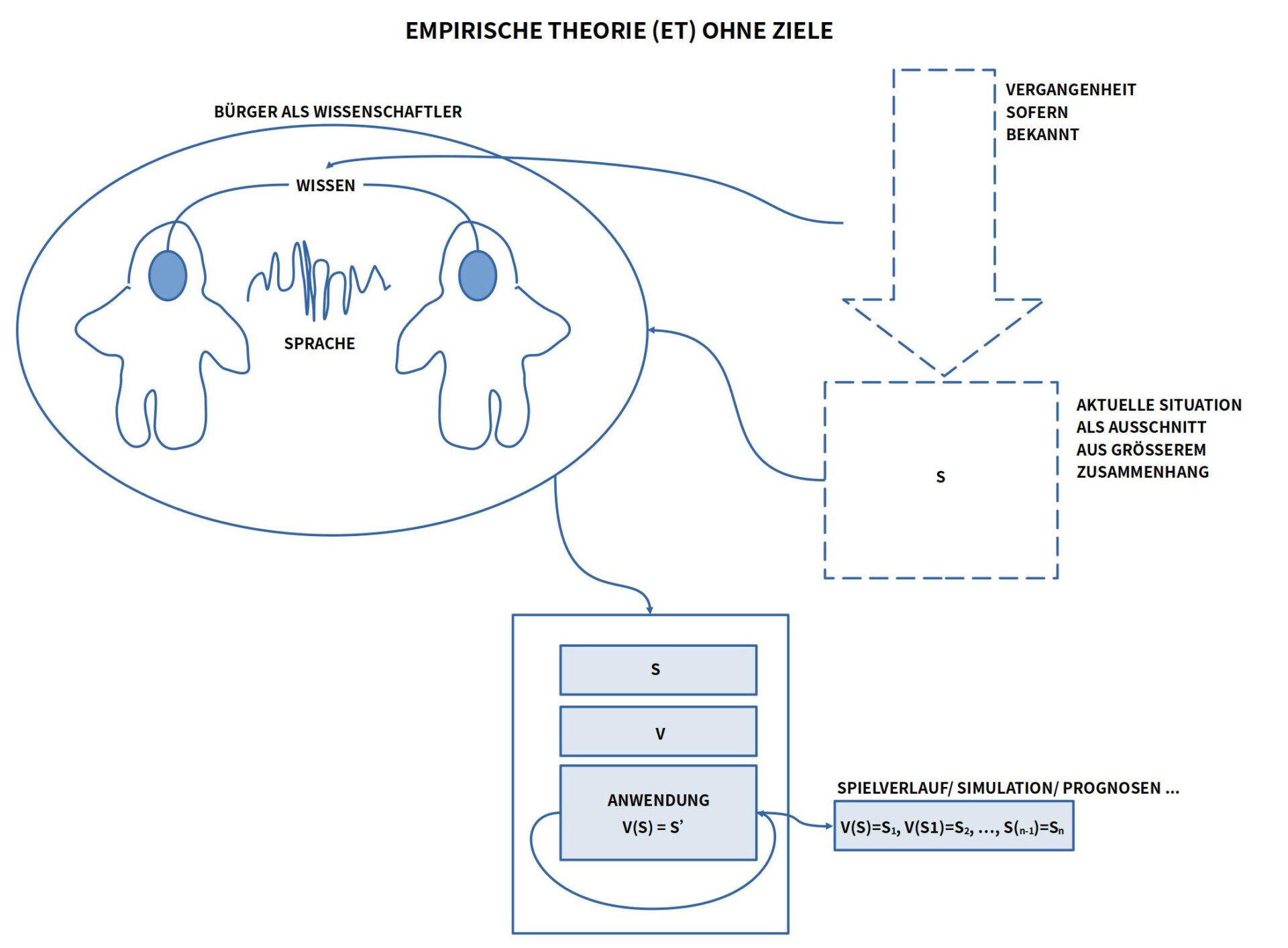
BILD : Skizze der Struktur einer empirischen Theorie ohne Ziele. Eine empirische Theorie (ET) mit Zielen wäre eine ’nachhaltige empirische Theorie (NET)‘. Siehe Text weiter unten.
Diese Skizze zeigt menschliche Akteure hier nicht als die Anwender einer Theorie — wie im Beispiel eines Brettspiels — sondern als Autoren einer Theorie, also jene Menschen, die Theorien in Interaktion mit dem realen Alltag entwickeln.
Hier wird davon ausgegangen, dass Theorie-Autoren im Normalfall irgendwelche Bürger sind, die ein Interesse eint, bestimmte Vorgänge in ihrem Alltag besser zu verstehen.
Zum Start müssen sie sich darauf einigen, welchen Ausschnitt aus ihrem Alltag sie als Startsituation (S) benutzen wollen. Diese Startsituation muss in einem Text beschrieben werden, der sich von allen Beteiligten als im Alltag zutreffend (wahr) erweist.
Aufgrund des verfügbaren Wissens über die bisherige Vergangenheit müssen die Theorie-Autoren sich darauf einigen, welche Arten von Veränderungen (V) sie für ihre Theorie benutzen wollen.
Schließlich müssen sie sich auch darüber einigen, auf welche Weise die ausgewählten Veränderungsbeschreibungen (V) auf eine gegebene Situation (S) so angewendet werden können, dass sich dadurch die Beschreibung jener Situation S1 ergibt, die durch die angewendeten Veränderungen entsteht. Abkürzend geschrieben: V(S)=S1.
Da sich in den meisten Fällen die angenommenen Veränderungsregeln V auch auf die neue nachfolgende Situation S1 wieder anwenden lässt — also V(S1)=S2 usw. –, reichen diese drei Elemente <S, V, Anwendung> aus, um aus einer Gegenwart S heraus mit Hilfe von Veränderungswissen bestimmte Zustände als möglich in einer Zukunft zu prognostizieren.
Dies beschreibt die Struktur und den Inhalt einer gewöhnlichen empirischen Theorie (ET).
Nachhaltige Empirische Theorie (NET) = ET + Ziele
Der Übergang von einer normalen empirischen Theorie (ET) zu einer nachhaltigen empirischen Theorie (NET) ist vergleichsweise einfach: man muss nur das empirische Wissen mit solchen Zielen (Z) verknüpfen, die aus der Gesellschaft heraus als interessante Kandidaten für eine mögliche gute Zukunft erwachsen.
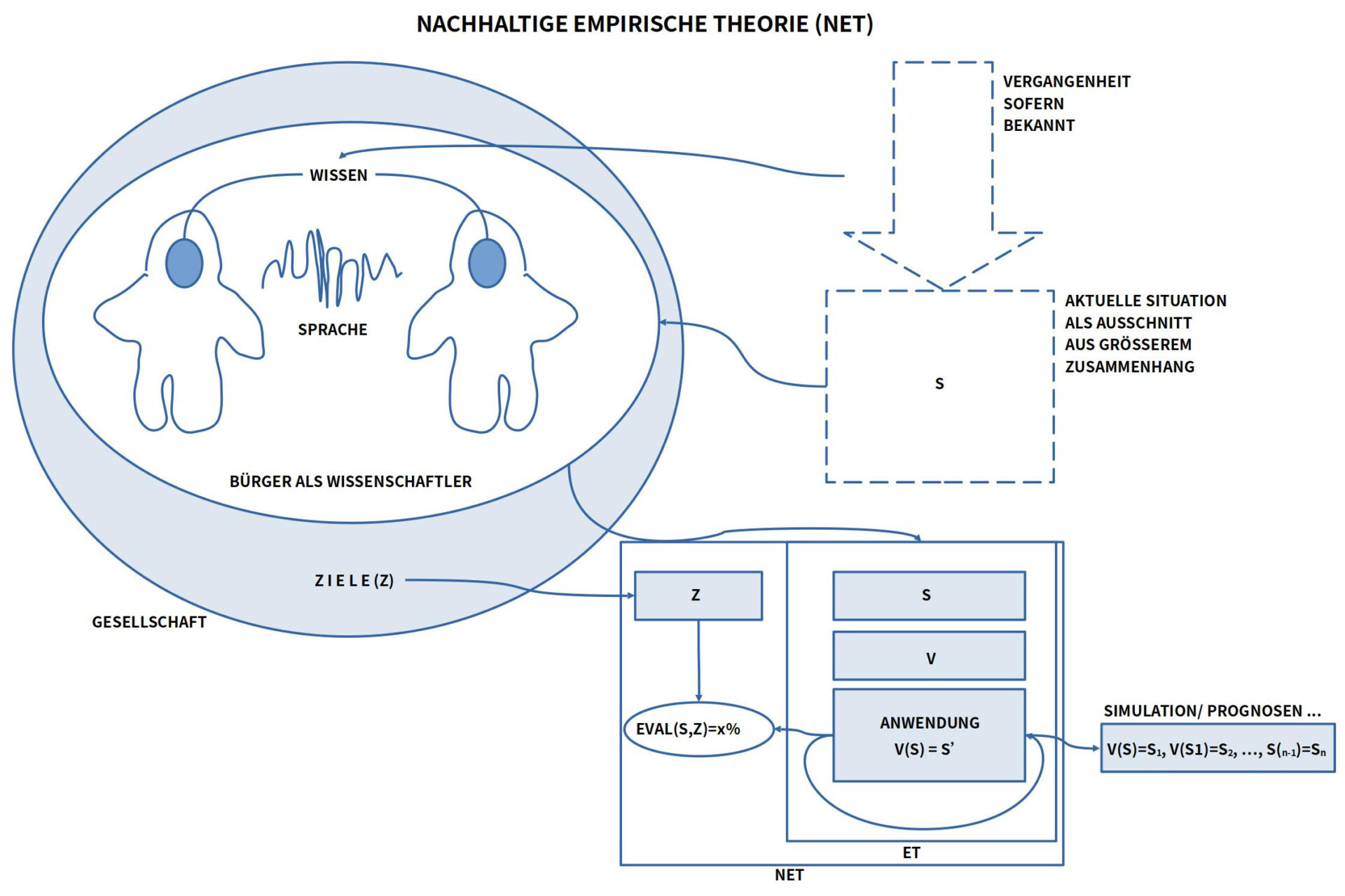
BILD : Ergänzend zur normalen empirischen Theorie (ET) kann die Gesellschaft, die den Kontext zu einer empirischen Theorie bildet, Ziele (Z) generieren, von denen sie glaubt, dass sie für möglichst viele eine möglichst gute Zukunft unterstützen. Formulierte Ziele können zugleich als Benchmark benutzt werden, um aktuelle Zustände S daraufhin zu evaluieren, welche große Übereinstimmung (in %) sie mit dem gewählten Ziel Z aufweisen.
Während empirisches Wissen als solches wertneutral ist, d.h. keine bestimmte Richtung in eine mögliche Zukunft favorisiert, können aber die Wertvorstellungen, die die Auswahl von realen Fragestellungen leiten, indirekt dazu führen, dass wichtiges Wissen aufgrund von der Wissenschaft vorgelagerten Entscheidungen nicht generiert wird. 12]
Fortsetzung: Teil 2
Kann Maschinelles Lernen im Format einer generativen KI einen Beitrag zur Bildung von nachhaltigen empirischen Theorien (NET) leisten?
QUELLEN
[1] Eliza Computer Programm in wkp-en: https://en.wikipedia.org/wiki/ELIZA, ELIZA is an early natural language processing computer program developed from 1964 to 1967[1] at MIT by Joseph Weizenbaum.[2][3] Created to explore communication between humans and machines, ELIZA simulated conversation by using a pattern matching and substitution methodology that gave users an illusion of understanding on the part of the program, but had no representation that could be considered really understanding what was being said by either party.[4][5][6]
[2] Joseph Weizenbaum, ELIZA A Computer Program For the Study of Natural Language Communication Between Man And Machine, Communications of the ACM Volume 9 / Number 1, January 1966, pp: 36-45
[3] chatbot in wkp-de: https://de.wikipedia.org/wiki/Chatbot, „Ein Chatterbot, Chatbot oder kurz Bot ist ein textbasiertes Dialogsystem, das Chatten mit einem technischen System erlaubt. Er hat je einen Bereich zur Textein- und -ausgabe, über die sich in natürlicher Sprache mit dem System kommunizieren lässt. Chatbots können, müssen aber nicht in Verbindung mit einem Avatar benutzt werden. Technisch sind Chatbots näher mit einer Volltextsuchmaschine verwandt als mit künstlicher oder gar natürlicher Intelligenz. Mit der steigenden Computerleistung können Chatbot-Systeme allerdings immer schneller auf immer umfangreichere Datenbestände zugreifen und daher auch intelligente Dialoge für den Nutzer bieten, wie zum Beispiel das bei OpenAI entwickelte ChatGPT oder das von Google LLC vorgestellte Language Model for Dialogue Applications (LaMDA). Solche Systeme werden auch als virtuelle persönliche Assistenten bezeichnet. Es gibt auch Chatbots, die gar nicht erst versuchen, wie ein menschlicher Chatter zu wirken (daher keine Chatterbots), sondern ähnlich wie IRC-Dienste nur auf spezielle Befehle reagieren. Sie können als Schnittstelle zu Diensten außerhalb des Chats dienen, oder auch Funktionen nur innerhalb ihres Chatraums anbieten, z. B. neu hinzugekommene Chatter mit dem Witz des Tages begrüßen. Heute wird meistens durch digitale Assistenten wie Google Assistant und Amazon Alexa, über Messenger-Apps wie Facebook Messenger oder WhatsApp oder aber über Organisationstools und Webseiten auf Chatbots zugegriffen[1][2].“
[4] Generative KI als ‚Generativer Vortrainierter Transformer‘ (Generative pre-trained transformers GPT) in wkp-de, https://de.wikipedia.org/wiki/Generativer_vortrainierter_Transformer, „Generative vortrainierte Transformer (englisch Generative pre-trained transformers, GPT) sind eine Art großes Sprachmodell[1][2][3] und ein bedeutendes Framework für generative künstliche Intelligenz.[4][5] Der erste GPT wurde 2018 vom amerikanischen Unternehmen für künstliche Intelligenz (KI) OpenAI vorgestellt.[6] GPT-Modelle sind künstliche neuronale Netzwerke, die auf der Transformer–Architektur basieren, auf großen Datensätzen unbeschrifteten Textes vorab trainiert werden und in der Lage sind, neuartige, menschenähnliche Inhalte zu generieren.[2] Bis 2023 haben die meisten LLMs diese Eigenschaften[7] und werden manchmal allgemein als GPTs bezeichnet.[8] OpenAI hat sehr einflussreiche GPT-Grundmodelle veröffentlicht, die fortlaufend nummeriert wurden und die „GPT-n“-Serie bilden. Jedes dieser Modelle war signifikant leistungsfähiger als das vorherige, aufgrund zunehmender Größe (Anzahl der trainierbaren Parameter) und des Trainings. Das jüngste dieser Modelle, GPT-4, wurde im März 2023 veröffentlicht. Solche Modelle bilden die Grundlage für ihre spezifischeren GPT-Systeme, einschließlich Modellen, die für die Anweisungsbefolgung optimiert wurden und wiederum den ChatGPT–Chatbot-Service antreiben.[1] Der Begriff „GPT“ wird auch in den Namen und Beschreibungen von Modellen verwendet, die von anderen entwickelt wurden. Zum Beispiel umfasst eine Reihe von Modellen, die von EleutherAI erstellt wurden, weitere GPT-Grundmodelle. Kürzlich wurden auch sieben Modelle von Cerebras erstellt. Auch Unternehmen in verschiedenen Branchen haben auf ihren jeweiligen Gebieten aufgabenorientierte GPTs entwickelt, wie z. B. „EinsteinGPT“ von Salesforce (für CRM)[9] und „BloombergGPT“ von Bloomberg (für Finanzen).[10]„
[4a] Die Firma openAI: https://openai.com/
[4b] Kurze Beschreibung: https://en.wikipedia.org/wiki/ChatGPT
[4c] Tutorial zu chatGPT: https://blogkurs.de/chatgpt-prompts/
[5] Person-Centered Therapy in wkp-en: https://en.wikipedia.org/wiki/Person-centered_therapy
[6] Messung in wkp-de: https://de.wikipedia.org/wiki/Messung
[7] Mensch ärgere Dich nicht in wkp-de: https://de.wikipedia.org/wiki/Mensch_%C3%A4rgere_Dich_nicht
[8] Elain Rich, 1983, Artificial Intelligence. McGraw-Hill Book Company. Anmerkung: In der Informatik der 1970iger und 1980iger Jahre hatte man gemerkt, dass die Beschränkung auf die Logik als Beschreibung von Realität zu einfach und zu umständlich ist. Konfrontiert mit dem Alltag wurden Begriffe aktiviert wie ‚Schema‘, ‚Frame (Rahmen)‘, ‚Script‘, ‚Stereotype‘, ‚Rule Model (Rollenmodell)‘. Doch wurden diese Konzepte letztlich noch sehr starr verstanden und benutzt. Siehe Kap.7ff bei Rich.
[9] Natürlich gibt es auch Spiele, die einen Umfang haben, der von den Spielern eine sehr intensive Beschäftigung verlangt, um sie wirklich voll zu verstehen. Ermöglichen solche komplexe Spiele aber zugleich wertvolle ‚Emotionen/ Gefühle‘ in den Spielern, dann wirkt die Komplexität nicht abschreckend, sondern kann zu einer lang anhaltenden Quelle von Spiellust werden, die in Spielsucht übergehen kann (und vielfach auch tatsächlich in Spielsucht übergeht).
[10] Warren Weaver, Science and the Citizens, Bulletion of the Atomic Scientists, 1957, Vol 13, pp. 361-365.
[11] Philipp Westermeier, 23.Nov. 2022, Besprechung Science and the Citizen von Warren Weaver, URL: https://www.oksimo.org/2022/11/23/besprechung-science-and-the-citizen-von-warren-weaver/
[12] Indirekt kann empirisches Wissen einen gewissen Einfluss auf eine mögliche Zukunft ausüben, indem bei der Auswahl einer zu erstellenden empirische Theorie (ET) gerade solche Aspekte nicht ausgewählt werden, die vielleicht für eine bestimmte Zielerreichung wichtig wären, jetzt aber eben nicht verfügbar sind. Dies kann sich vielfach manifestieren, z.B. durch eine Forschungspolitik, die von vornherein viele Themenfelder ausblendet, weil sie im Lichte aktueller Trends als nicht vorteilhaft eingestuft werden.
DER AUTOR
Einen Überblick über alle Beiträge von Autor cagent nach Titeln findet sich HIER.