Journal: Philosophie Jetzt – Menschenbild
ISSN 2365-5062, 13.Februar 2023 – 17.April 2023
URL: cognitiveagent.org, Email: info@cognitiveagent.org
Autor: Gerd Doeben-Henisch (cagent@cognitiveagent.org)
Kontext
Seit der Freigabe des chatbots ‚chatGPT‘ für die größere Öffentlichkeit geht eine Art ‚Erdbeben‘ durch die Medien, weltweit, in vielen Bereichen, vom Privatpersonen über Institutionen, Firmen, Behörden …. jeder sucht das ‚chatGPT Erlebnis‘. Diese Reaktionen sind erstaunlich, und erschreckend zugleich.
Anmerkung: In meinem Englischen Blog hatte ich nach einigen Experimenten mit chatGPT eine erste Reflexion über den möglichen Nutzen von chatGPT geschrieben. Mir hatte es für ein erstes Verständnis geholfen; dieses hat sich dann bis zu dem Punkt weiterentwickelt, der im vorliegenden Text zum Ausdruck kommt.[6]
Form
Die folgenden Zeilen bilden nur eine kurze Notiz, da es sich kaum lohnt, ein ‚Oberflächenphänomen‘ so intensiv zu diskutieren, wo doch die ‚Tiefenstrukturen‘ erklärt werden sollten. Irgendwie scheinen die ‚Strukturen hinter chatGPT‘ aber kaum jemanden zu interessieren (Gemeint sind nicht die Details des Quellcodes in den Algortihmen).
chatGPT als Objekt
Der chatbot mit Namen ‚chatGPT‘ ist ein Stück Software, ein Algorithmus, der (i) von Menschen erfunden und programmiert wurde. Wenn (ii) Menschen ihm Fragen stellen, dann (iii) sucht er in der ihm bekannten Datenbank von Dokumenten, die wiederum Menschen erstellt haben, (iv) nach Textmustern, die nach bestimmten formalen Kriterien (z.T. von den Programmierern vorgegeben) einen Bezug zur Frage aufweisen. Diese ‚Textfunde‘ werden (v) ebenfalls nach bestimmten formalen Kriterien (z.T. von den Programmierern vorgegeben) in einen neuen Text ‚angeordnet‘, der (vi) jenen Textmustern nahe kommen soll, die ein menschlicher Leser ‚gewohnt‘ ist, als ’sinnvoll‘ zu akzeptieren.
Textoberfläche – Textbedeutung – Wahrheitsfähig
Ein normaler Mensch kann — mindestens ‚intuitiv‘ — unterscheiden zwischen den (i) ‚Zeichenketten‘, die als ‚Ausdrücke einer Sprache‘ benutzt werden, und jenen (ii) ‚Wissenselementen‘ (im Kopf des Hörer-Sprechers), die als solche ‚unabhängig‘ sind von den Sprachelementen, aber die (iii) von Sprechern-Hörer einer Sprache ‚frei assoziiert‘ werden können, so dass die korrelierten ‚Wissenselemente zu dem werden, was man gewöhnlich die ‚Bedeutung‘ der Sprachelemente nennt.[1] Von diesen Wissenselementen (iv) ‚weiß‘ jeder Sprachteilnehmer schon ‚vorsprachlich‘, als lernendes Kind [2], dass einige dieser Wissenselemente unter bestimmten Umständen mit Umständen der Alltagswelt ‚korrelierbar‘ sind. Und der normale Sprachbenutzer verfügt auch ‚intuitiv‘ (automatisch, unbewusst) über die Fähigkeit, solche Korrelation — im Lichte des verfügbaren Wissens — einzuschätzen als (v) ‚möglich‘ oder (vi) als eher ‚unwahrscheinlich‘ bzw. (vi) als ‚bloße Fantasterei‘.[3]
Die grundlegende Fähigkeit eines Menschen, eine ‚Korrelation‘ von Bedeutungen mit (intersubjektiven) Umweltgegebenheiten feststellen zu können, nennen — zumindest einige — Philosophen ‚Wahrheitsfähigkeit‘ und im Vollzug der Wahrheitsfähigkeit spricht man dann auch von ‚zutreffenenden‘ sprachlichen Äußerungen oder von ‚wahren (empirischen) Aussagen‘.[5]
Unterscheidungen wie ‚zutreffend‘ (‚wahr‘), ‚möglicherweise zutreffend‘, ‚eher nicht zutreffend‘ oder ‚auf keinen Fall zutreffend‘ deuten an, dass der Wirklichkeitsbezug menschlicher Wissenselemente sehr vielfältig und ‚dynamisch‘ ist. Etwas, das gerade noch zutreffend war, kann im nächsten Moment nicht mehr zutreffend sein. Etwas, das lange als ‚bloße Fantasterei‘ abgetan wurde, kann dann doch plötzlich als ‚möglich‘ erscheinen oder ‚trifft plötzlich zu‘. Sich in diesem ‚dynamisch korrelierten Bedeutungsraum‘ so zu bewegen, dass eine gewisse ‚innere und äußere Konsistenz‘ gewahrt bleibt, stellt eine komplexe Herausforderung dar, die von Philosophie und den Wissenschaften bislang eher nicht ganz verstanden, geschweige denn auch nur annähernd ‚erklärt‘ worden ist.
Fakt ist: wir Menschen können dies bis zu einem gewissen Grad. Je komplexer der Wissensraum ist, je vielfältiger die sprachlichen Interaktion mit anderen Menschen werden, umso schwieriger wird es natürlich.
‚Luftnummer‘ chatGPT
(Letzte Änderung: 15.Februar 2023, 07:25h)
Vergleicht man den chatbot chatGPT mit diesen ‚Grundeigenschaften‘ des Menschen, dann kann man erkennen, dass chatGPT nichts von alledem kann. (i) Fragen kann er von sich aus nicht sinnvoll stellen, da es keinen Anlass gibt, warum er fragen sollte (es sei denn, jemand induziert ihm eine Frage). (ii) Textdokumente (von Menschen) sind für ihn Ausdrucksmengen, für die er über keine eigenständigen Bedeutungszuordnung verfügt. Er könnte also niemals eigenständig die ‚Wahrheitsfrage‘ — mit all ihren dynamischen Schattierungen — stellen oder beantworten. Er nimmt alles für ‚bare Münze‘ bzw. man sagt gleich, dass er ’nur träumt‘.
Wenn chatGPT aufgrund seiner großen Text-Datenbank eine Teilmenge von Ausdrücken hat, die irgendwie als ‚wahr‘ klassifiziert sind, dann kann der Algorithmus ‚im Prinzip‘ indirekt ‚Wahrscheinlichkeiten‘ ermitteln, die andere Ausdrucksmengen, die nicht als ‚wahr‘ klassifiziert sind, dann doch ‚mit einer gewissen Wahrscheinlichkeit‘ als ‚wahr erscheinen‘
lassen. Ob der aktuelle chatGPT Algorithmus solche ‚wahrscheinlichen Wahrheiten explizit‘ benutzt, ist unklar. Im Prinzip übersetzt er Texte in ‚Vektorräume‘, die auf verschiedene Weise ‚ineinander abgebildet‘ werden, und Teile dieser Vektorräume werden dann wieder in Form eines ‚Textes‘ ausgegeben. Das Konzept ‚Wahrheit‘ taucht in diesen mathematischen Operationen — nach meinem aktuellen Kenntnisstand — nicht auf. Wenn, dann wäre es auch nur der formale logische Wahrheitsbegriff [4]; dieser liegt aber mit Bezug auf die Vektorräume ‚oberhalb‘ der Vektorräume, bildet in Bezug auf diese einen ‚Meta-Begriff‘. Wollte man diesen auf die Vektorräume und Operationen auf diesen Vektorräumen tatsächlich anwenden, dann müsste man den Code von chatGPT komplett neu schreiben. Würde man dies tun — das wird aber keiner schaffen — dann würde sich der Code von chatGPT dem Status einer formalen Theorie nennen (wie in der Mathematik) (siehe Anmerkung [5]). Von einer empirischen Wahrheitsfähigkeit wäre chatGPT dann immer noch meilenweit entfernt.
Hybride Scheinwahrheiten
Im Anwendungsfall, bei dem der Algorithmus mit Namen ‚chatGPT‘ Ausdrucksmengen benutzt, die den Texten ähneln, die Menschen produzieren und lesen, navigiert sich chatGPT rein formal und mit Wahrscheinlichkeiten durch den Raum der formalen Ausdruckselemente. Ein Mensch, der die von chatGPT produzierten Ausdrucksmengen ‚liest‘, aktiviert aber automatisch (= unbewusst!) sein eigenes ’sprachliches Bedeutungswissen‘ und projiziert dieses in die abstrakten Ausdrucksmenge von chatGBT. Wie man beobachten kann (und hört und liest von anderen), sind die von chatGBT produzierten abstrakten Ausdrucksmengen dem gewöhnten Textinput von Menschen in vielen Fällen — rein formal — so ähnlich, dass ein Mensch scheinbar mühelos seine Bedeutungswissen mit diesen Texten korrelieren kann. Dies hat zur Folge, dass der rezipierende (lesende, hörende) Mensch das ‚Gefühl‘ hat, chatGPT produziert ’sinnvolle Texte‘. In der ‚Projektion‘ des lesenden/hörenden Menschen JA, in der Produktion von chatGPT aber NEIN. chatGBT verfügt nur über formale Ausdrucksmengen (kodiert als Vektorräume), mit denen er ‚blind‘ herumrechnet. Über ‚Bedeutungen‘ im menschlichen Sinne verfügt er nicht einmal ansatzweise.
Zurück zum Menschen?
(Letzte Änderung: 27.Februar 2023)
Wie leicht sich Menschen von einer ‚fake-Maschine‘ so beeindrucken lassen, dass sie dabei sich selbst anscheinend vergessen und sich ‚dumm‘ und ‚leistungsschwach‘ fühlen, obgleich die Maschine nur ‚Korrelationen‘ zwischen menschlichen Fragen und menschlichen Wissensdokumenten rein formal herstellt, ist eigentlich erschreckend [7a,b], und zwar mindestens in einem doppelten Sinne: (i)Statt die eigene Potentiale besser zu erkennen (und zu nutzen), starrt man gebannt wie das berühmte ‚Kaninchen auf die Schlange‘, obgleich die Maschine immer noch ein ‚Produkt des menschlichen Geistes‘ ist. (ii) Durch diese ‚kognitive Täuschung‘ wird versäumt, das tatsächlich ungeheure Potential ‚kollektiver menschlicher Intelligenz‘ besser zu verstehen, das man dann natürlich durch Einbeziehung moderner Technologien um mindestens einen evolutionären Level weiter voran bringen könnte. Die Herausforderung der Stunde lautet ‚Kollektiver Mensch-Maschine Intelligenz‘ im Kontext einer nachhaltigen Entwicklung mit Priorität bei der menschlichen kollektiven Intelligenz. Die aktuelle sogenannte ‚Künstliche (= maschinelle) Intelligenz‘ sind ziemlich primitive Algorithmen. Integriert in eine entwickelte ‚kollektive menschliche Intelligenz‘ könnten ganz andere Formen von ‚Intelligenz‘ realisiert werden, solche, von denen wir aktuell höchstens träumen können.
Kommentierung weiterer Artikel von anderen Autoren zu chatGPT
(Letzte Änderung: 17.April 2023)
Achtung: Einige der Text in den Anmerkungen sind aus dem Englischen zurück übersetzt worden. Dies geschah unter Benutzung der Software www.DeepL.com/Translator (kostenlose Version).
Siehe [8], [9], [10], [12],[13],[14],[15]
Anmerkungen
[1] In den vielen tausend ’natürlichen Sprachen‘ dieser Welt kann man beobachten, wie ‚erfahrbare Umweltgegebenheiten‘ über die ‚Wahrnehmung‘ zu ‚Wissenselementen‘ werden können, die dann in jeder Sprache mit unterschiedlichen Ausdrücken korreliert werden. Die Sprachwissenschaftler (und Semiotiker) sprechen daher hier von ‚Konventionen‘, ‚frei vereinbarte Zuordnungen‘.
[2] Aufgrund der körperlichen Interaktion mit der Umgebung, die ‚Wahrnehmungsereignisse‘ ermöglicht, die von den ‚erinnerbaren und gewussten Wissenselementen‘ unterscheidbar sind.
[3] Die Einstufung von ‚Wissenselementen‘ als ‚Fantasterei‘ kann falsch sein, wie viele Beispiele zeigen, wie umgekehrt, die Einstufung als ‚wahrscheinlich korrelierbar‘ auch falsch sein kann!
[4] Nicht der ‚klassischen (aristotelischen) Logik‘ da diese noch keine strenge Trennung von ‚Form‘ (Ausdruckselementen) und ‚Inhalt‘ (Bedeutung) kannte.
[5] Es gibt auch Kontexte, in denen spricht man von ‚wahren Aussagen‘, obgleichgar keine Beziehung zu einer konkreten Welterfahrung vorliegt. So z.B. im Bereich der Mathematik, wo man gerne sagt, dass eine Aussage ‚wahr‘ ist. Dies ist aber eine ganz ‚andere Wahrheit‘. Hier geht es darum, dass im Rahmen einer ‚mathematischen Theorie‘ bestimmte ‚Grundannahmen‘ gemacht wurden (die mit einer konkreten Realität nichts zu tun haben müssen), und man dann ausgehend von diesen Grundannahmen mit Hilfe eines formalen Folgerungsbegriffs (der formalen Logik) andere Aussagen ‚ableitet‘. Eine ‚abgeleitete Aussage‘ (meist ‚Theorem‘ genannt), hat ebenfalls keinerlei Bezug zu einer konkreten Realität. Sie ist ‚logisch wahr‘ oder ‚formal wahr‘. Würde man die Grundannahmen einer mathematischen Theorie durch — sicher nicht ganz einfache — ‚Interpretationen‘ mit konkreter Realität ‚in Beziehung setzen‘ (wie z.B. in der ‚angewandten Physik‘), dann kann es unter speziellen Bedingungen sein, dass die formal abgeleiteten Aussagen einer solchen ‚empirisch interpretierten abstrakten Theorie‘ eine ‚empirische Bedeutung‘ gewinnen, die unter bestimmten Bedingungen vielleicht ‚korrelierbar‘ ist; dann würde man solche Aussagen nicht nur ‚logisch wahr‘ nennen, sondern auch ‚empirisch wahr‘. Wie die Geschichte der Wissenschaft und der Wissenschaftsphilosophie zeigt, ist der aber ‚Übergang‘ von empirisch interpretierten abstrakten Theorien zu empirisch interpretierbaren Folgerungen mit Wahrheitsanspruch nicht trivial. Der Grund liegt im benutzten ‚logischen Folgerungsbegriff‘. In der modernen formalen Logik gibt es mahezu ‚beliebig viele‘ verschiedene formale Folgerzungsbegriffe. Ob ein solcher formaler Folgerungsbegriff tatsächlich die Struktur empirischer Gegebenheiten über abstrakte Strukturen mit formalen Folgerungen ‚angemessen wiedergibt‘, ist keinesfalls gesichert! Diese Problemstellung ist in der Wissenschaftsphilosophie bislang nicht wirklich geklärt!
[6] Gerd Doeben-Henisch, 15.-16.Januar 2023, „chatGBT about Rationality: Emotions, Mystik, Unconscious, Conscious, …“, in: https://www.uffmm.org/2023/01/15/chatgbt-about-rationality-emotions-mystik-unconscious-conscious/
[7a] Der chatbot ‚Eliza‘ von Weizenbaum von 1966 war trotz seiner Einfachheit in der Lage, menschliche Benutzer dazu zu bringen, zu glauben, dass das Programm sie ‚versteht‘ selbst dann, wenn man ihnen erklärte, dass es nur ein einfacher Algorithmus sei. Siehe das Stichwort ‚Eliza‘ in wkp-de: https://de.wikipedia.org/wiki/ELIZA
[7b] Joseph Weizenbaum, 1966, „ELIZA. A Computer Program For the Study of Natural Language. Communication Between Man And Machine“, Communications of the ACM, Vol.9, No.1, January 1966, URL: https://cse.buffalo.edu/~rapaport/572/S02/weizenbaum.eliza.1966.pdf Anmerkung: Obwohl das Programm ‚Eliza‘ von Weizenbaum sehr einfach war, waren alle Benutzer fasziniert von dem Programm, weil sie das Gefühl hatten „Es versteht mich“, dabei spiegelte das Programm nur die Fragen und Aussagen der Benutzer. Anders gesagt: die Benutzer waren ‚von sich selbst‘ fasziniert mit dem Programm als eine Art ‚Spiegel‘.
[8] Ted Chiang, 2023, „ChatGPT Is a Blurry JPEG of the Web. OpenAI’s chatbot offers paraphrases, whereas Google offers quotes. Which do we prefer?“, The NEW YORKER, February 9, 2023. URL: https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web . Anmerkung: Chang betrachtet das Programm chatGPT im Paradigma eines ‚Kompressions-Algorithmus‘: Die Fülle der Informationen wird ‚verdichtet/ abstrahiert‘, so dass ein leicht unscharfes Bild der Textmengen entsteht, keine 1-zu-1 Kopie. Dies führt beim Benutzer zum Eindruck eines Verstehens auf Kosten des Zugriffs auf Details und Genauigkeit. Die Texte von chatGPT sind nicht ‚wahr‘, aber sie ‚muten an‘.
[9] Dietmar Hansch, 2023, „Der ehrlichere Name wäre ‚Simulierte Intelligenz‘. An welchen Defiziten Bots wie chatGBT leiden und was das für unseren Umgang mit Ihnen heißen muss.“, FAZ, 1.März 2023, S.N1 . Bemerkung: Während Chiang (siehe [8] sich dem Phänomen chatGPT mit dem Konzept ‚Kompressions-Algorithmus‘ nähert bevorzugt Hansch die Begriffe ’statistisch-inkrementelles Lernen‘ sowie ‚Einsichtslernen‘. Für Hansch ist Einsichtslernen an ‚Geist‘ und ‚Bewusstsein‘ gebunden, für die er im Gehirn ‚äquivalente Strukturen‘ postuliert. Zum Einsichtslernen kommentiert Hansch weiter „Einsichtslernen ist nicht nur schneller, sondern auch für ein tiefes, ganzheitliches Weltverständnis unverzichtbar, das weit greifende Zusammenhänge erfasst sowie Kriterien für Wahrheit und Wahrhaftigkeit vermittelt.“ Es verwundert dann nicht wenn Hansch schreibt „Einsichtslernen ist die höchster Form des Lernens…“. Mit Bezug auf diesen von Hansch etablierten Referenzrahmen klassifiziert er chatGPT in dem Sinne dass er nur zu ’statistisch-inkrementellem Lernen‘ fähig sei. Ferner postuliert Hansch für den Menschen, „Menschliches Lernen ist niemals rein objektiv, wir strukturieren die Welt immer in Bezug auf unsere Bedürfnisse, Gefühle und bewussten Zwecke…“. Er nennt dies den ‚Humanbezug‘ im menschlichen Erkennen, und genau diesen spricht er chatGPT auch ab. Für geläufige Bezeichnung ‚KI‘ als ‚Künstliche Intelligenz‘ postuliert er, dass der Terminus ‚Intelligenz‘ in dieser Wortverbindung nichts mit der Bedeutung zu tun habe, die wir im Fall des Menschen mit ‚Intelligenz‘ verbinden, also auf keinen Fall etwas mit ‚Einsichtslernen‘, wie er zuvor schon festgestellt hat. Um diesem Umstand mehr Ausdruck zu verleihen würde er lieber den Begriff ‚Simulierte Intelligenz‘ benutzen (siehe dazu auch [10]). Diese begriffliche Strategie wirkt merkwürdig, da der Begriff Simulation [11] normalerweise voraussetzt, dass es eine klare Sachlage gibt, zu der man ein vereinfachtes ‚Modell‘ definiert, mittels dem sich dann das Verhalten des Originalsystems in wichtigen Punkten — vereinfacht — anschauen und untersuchen lässt. Im vorliegenden Fall ist aber nicht ganz klar, was denn überhaupt das Originalsystem sein soll, das im Fall von KI simuliert werden soll. Es gibt bislang keine einheitliche Definition von ‚Intelligenz‘ im Kontext von ‚KI‘! Was die Begrifflichkeit von Hansch selbst angeht, so sind die Begriffe ‚statistisch-inkrementelles Lernen‘ sowie ‚Einsichtslernen‘ ebenfalls nicht klar definiert; der Bezug zu beobachtbarem menschlichen Verhalten geschweige den zu den postulierten ‚äquivalenten Gehirnstrukturen‘ ist beliebig unklar (was durch den Bezug zu bis heute nicht definierten Begriffen wie ‚Bewusstsein‘ und ‚Geist‘ nicht gerade besser wird).
[10] Severin Tatarczyk, 19.Februar 2023, zu ‚Simulierter Intelligenz‘: https://www.severint.net/2023/02/19/kompakt-warum-ich-den-begriff-simulierte-intelligenz-bevorzuge-und-warum-chatbots-so-menschlich-auf-uns-wirken/
[11] Begriff ‚Simulation‘ in wkp-de: https://de.wikipedia.org/wiki/Simulation
[12] Doris Brelowski machte mich auf folgenden Artikel aufmerksam: James Bridle, 16.März 2023, „The stupidity of AI. Artificial intelligence in its current form is based on the wholesale appropriation of existing culture, and the notion that it is actually intelligent could be actively dangerous“, URL: https://www.theguardian.com/technology/2023/mar/16/the-stupidity-of-ai-artificial-intelligence-dall-e-chatgpt?CMP=Share_AndroidApp_Other . Anmerkung: Ein Beitrag, der kenntnisreich und sehr differenziert das Wechselspiel zwischen Formen der AI beschreibt, die von großen Konzernen auf das gesamte Internet ‚losgelassen‘ werden, und was dies mit der menschlichen Kultur und dann natürlich mit den Menschen selbst macht. Zwei Zitate aus diesem sehr lesenwerten Artikel: Zitat 1: „The entirety of this kind of publicly available AI, whether it works with images or words, as well as the many data-driven applications like it, is based on this wholesale appropriation of existing culture, the scope of which we can barely comprehend. Public or private, legal or otherwise, most of the text and images scraped up by these systems exist in the nebulous domain of “fair use” (permitted in the US, but questionable if not outright illegal in the EU). Like most of what goes on inside advanced neural networks, it’s really impossible to understand how they work from the outside, rare encounters such as Lapine’s aside. But we can be certain of this: far from being the magical, novel creations of brilliant machines, the outputs of this kind of AI is entirely dependent on the uncredited and unremunerated work of generations of human artists.“ Zitat 2: „Now, this didn’t happen because ChatGPT is inherently rightwing. It’s because it’s inherently stupid. It has read most of the internet, and it knows what human language is supposed to sound like, but it has no relation to reality whatsoever. It is dreaming sentences that sound about right, and listening to it talk is frankly about as interesting as listening to someone’s dreams. It is very good at producing what sounds like sense, and best of all at producing cliche and banality, which has composed the majority of its diet, but it remains incapable of relating meaningfully to the world as it actually is. Distrust anyone who pretends that this is an echo, even an approximation, of consciousness. (As this piece was going to publication, OpenAI released a new version of the system that powers ChatGPT, and said it was “less likely to make up facts”.)“
[13] David Krakauer in einem Interview mit Brian Gallagher in Nautilus, March 27, 2023, Does GPT-4 Really Understand What We’re Saying?, URL: https://nautil.us/does-gpt-4-really-understand-what-were-saying-291034/?_sp=d9a7861a-9644-44a7-8ba7-f95ee526d468.1680528060130. David Krakauer, Evolutionstheoretiker und Präsident des Santa Fe Instituts für Complexity Science, analysiert die Rolle von Chat-GPT-4-Modellen im Vergleich zum menschlichen Sprachmodell und einem differenzierteren Verständnis dessen, was „Verstehen“ und „Intelligenz“ bedeuten könnte. Seine Hauptkritikpunkte stehen in enger Übereinstimmung mit der obigen Position. Er weist darauf hin, dass (i) man klar zwischen dem „Informationskonzept“ von Shannon und dem Konzept der „Bedeutung“ unterscheiden muss. Etwas kann eine hohe Informationslast darstellen, aber dennoch bedeutungslos sein. Dann weist er darauf hin (ii), dass es mehrere mögliche Varianten der Bedeutung von „Verstehen“ gibt. Die Koordinierung mit dem menschlichen Verstehen kann funktionieren, aber Verstehen im konstruktiven Sinne: nein. Dann setzt Krakauer (iii) GPT-4 mit dem Standardmodell der Wissenschaft in Beziehung, das er als „parsimony“ charakterisiert; chat-GPT-4 ist eindeutig das Gegenteil. Ein weiterer Punkt (iv) ist die Tatsache, dass die menschliche Erfahrung einen „emotionalen“ und einen „physischen“ Aspekt hat, der auf somato-sensorischen Wahrnehmungen im Körper beruht. Dies fehlt bei GPT-4. Dies hängt (v) mit der Tatsache zusammen, dass das menschliche Gehirn mit seinen „Algorithmen“ das Produkt von Millionen von Jahren der Evolution in einer komplexen Umgebung ist. Die GPT-4-Algorithmen haben nichts Vergleichbares; sie müssen den Menschen nur ‚überzeugen‘. Schließlich (vi) können Menschen „physikalische Modelle“ generieren, die von ihren Erfahrungen inspiriert sind, und können mit Hilfe solcher Modelle schnell argumentieren. So kommt Krakauer zu dem Schluss: „Das Narrativ, das besagt, dass wir das menschliche Denken wiederentdeckt haben, ist also in vielerlei Hinsicht falsch. Einfach nachweislich falsch. Das kann nicht der richtige Weg sein.“ Anmerkungen zum Text von Krakauer: Benutzt man das allgemeine Modell von Akteur und Sprache, wie es der Text oben annimmt, dann ergeben sich die Punkt (i) – (vi) als Folgerungen aus dem allgemeinen Modell. Die Akzeptanz eines allgemeinen Akteur-Sprache Modells ist leider noch nicht verbreitet.
[14] Von Marie-José Kolly (Text) und Merlin Flügel (Illustration), 11.04.2023, „Chatbots wie GPT können wunderbare Sätze bilden. Genau das macht sie zum Problem“. Künstliche Intelligenz täuscht uns etwas vor, was nicht ist. Ein Plädoyer gegen die allgemeine Begeisterung. Online-Zeitung ‚Republik‘ aus der SChweiz, URL: https://www.republik.ch/2023/04/11/chatbots-wie-gpt-koennen-wunderbare-saetze-bilden-genau-das-macht-sie-zum-problem? Hier einige Anmerkungen:
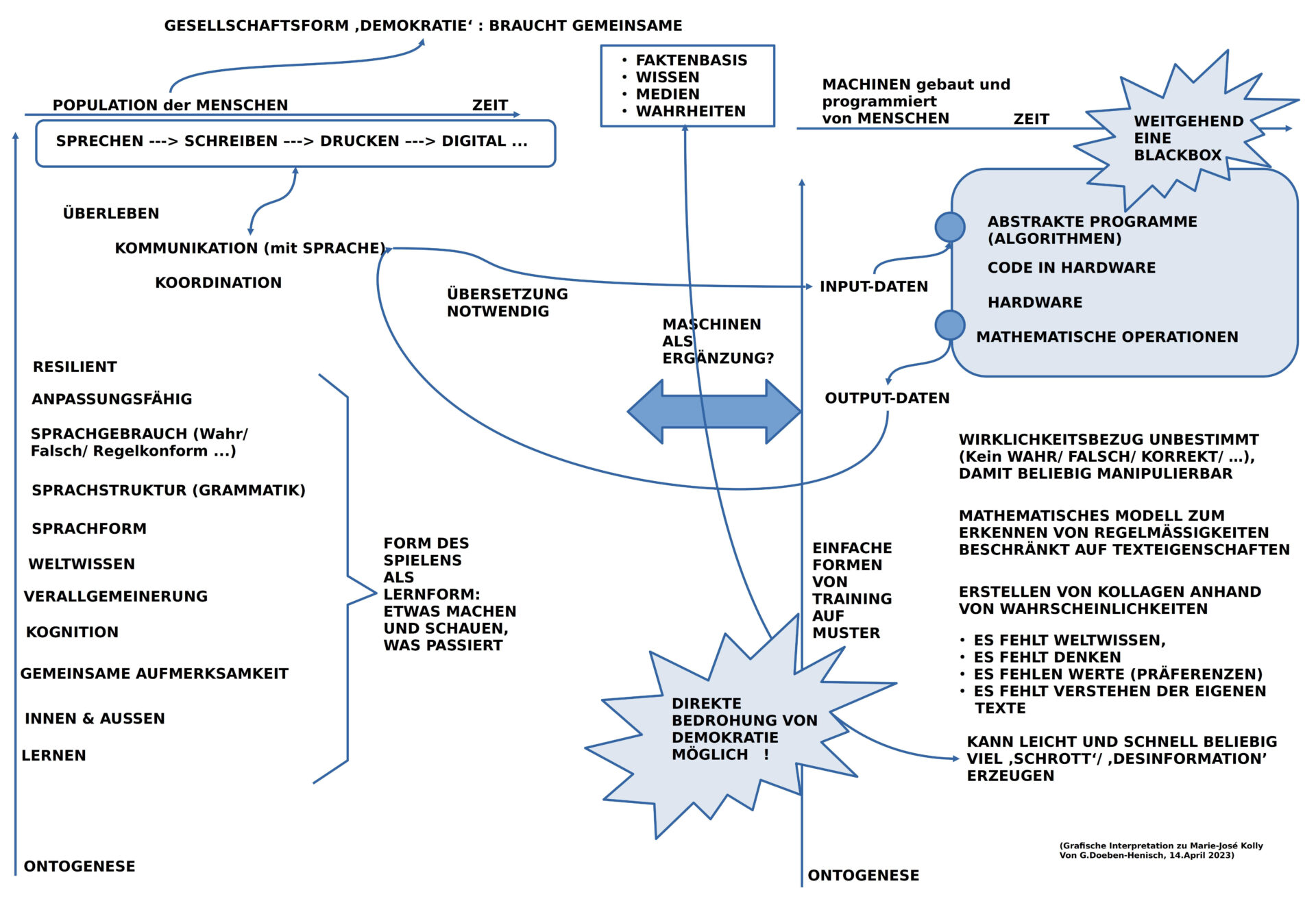
Der Text von Marie-José Kolly sticht hervor weil der Algorithmus mit Namen chatGPT(4) hier sowohl in seinem Input-Output Verhalten charakterisiert wird und zusätzlich ein Vergleich zum Menschen zumindest in Ansätzen vorgenommen wird.
Das grundsätzliche Problem des Algorithmus chatGPT(4) besteht darin (wie auch in meinem Text oben herausgestellt), dass er als Input-Daten ausschließlich über Textmengen verfügt (auch jene der Benutzer), die nach rein statistischen Verfahren in ihren formalen Eigenschaften analysiert werden. Auf der Basis der analysierten Regelmäßigkeiten lassen sich dann beliebige Text-Kollagen erzeugen, die von der Form her den Texten von Menschen sehr stark ähneln, so sehr, dass viele Menschen sie für ‚von Menschen erzeugte Texte‘ nehmen. Tatsächlich fehlen dem Algorithmus aber das, was wir Menschen ‚Weltwissen‘ nennen,es fehlt echtes ‚Denken‘, es fehlen ‚eigene‘ Werte-Positionen, und der Algorithmus ‚versteht‘ seine eigenen Text ’nicht‘.
Aufgrund dieses fehlenden eigenen Weltbezugs kann der Algorithmus über die verfügbaren Textmengen sehr leicht manipuliert werden. Eine ‚Massenproduktion‘ von ‚Schrott-Texten‘, von ‚Desinformationen‘ ist damit sehr leicht möglich.
Bedenkt man, dass moderne Demokratien nur funktionieren können, die Mehrheit der Bürger über eine gemeinsame Faktenbasis verfügt, die als ‚wahr‘ angenommen werden können, über eine gemeinsame Wissensmenge, über zuverlässige Medien, dann können mit dem Algorithmus chatGPT(4) genau diese Anforderungen an eine Demokratie massiv zerstört werden.
Interessant ist dann die Frage, ob chatGPT(4) eine menschliche Gesellschaft, speziell eine demokratische Gesellschaft, tatsächlich auch positiv-konstruktiv unterstützen kann?
Vom Menschen ist jedenfalls bekannt, dass dieser den Gebrauch seiner Sprache von Kindes Beinen an im direkten Kontakt mit einer realen Welt erlernt, weitgehend spielerisch, in Interaktion mit anderen Kindern/ Menschen. Für Menschen sind ‚Worte‘ niemals isolierte Größen sondern sie sind immer dynamisch eingebunden in ebenfalls dynamische Kontexte. Sprache ist nie nur ‚Form‘ sondern immer zugleich auch ‚Inhalt‘, und dies auf mannigfaltige Weise. Dies geht nur weil der Mensch über komplexe kognitiven Fähigkeiten verfügt, die u.a. entsprechende Gedächtnisleistungen wie auch Fähigkeiten zur Verallgemeinerung/ Generalisierung umfassen.
Die kulturgeschichtliche Entwicklung von gesprochener Sprache, über Schrift, Buch, Bibliotheken bis hin zu gewaltigen digitalen Datenspeichern hat zwar bezüglich der ‚formen‘ von Sprache und darin — möglicherweise — kodiertem Wissen Gewaltiges geleistet, aber es besteht der Eindruck, dass die ‚Automatisierung‘ der Formen diese in die ‚Isolation‘ treibt, so dass die Formen ihren Kontakt zur Realität, zur Bedeutung, zur Wahrheit immer mehr verlieren. Aus der Sprache als zentralem Moment der Ermöglichung von mehr komplexem Wissen und mehr komplexem Handeln wird damit zunehmend ein ‚Parasit‘, der immer mehr Raum beansprucht und dabei immer mehr Bedeutung und Wahrheit vernichtet.
[15] Gary Marcus, April 2023, Hoping for the Best as AI Evolves, Gary Marcus on the systems that “pose a real and imminent threat to the fabric of society.” Communications of the ACM, Volume 66, Issue 4, April 2023 pp 6–7, https://doi.org/10.1145/3583078 . Anmerkung: Gary Marcus schreibt anlässlich der Wirkungen von Systemen wie chatGPT(OpenAI), Dalle-E2 und Lensa über die ernst zunehmenden negativen Wirkungen, die diese Werkzeuge innerhalb einer Gesellschaft haben können, und zwar in einem Ausmaß, das eine ernsthafte Bedrohung für jede Gesellschaft darstellt! Sie sind inhärent fehlerhaft in den Bereichen Denken, Tatsachen und Halluzinationen. Mit nahezu Null Kosten lassen sich mit ihnen sehr schnell umfangreiche Desinformationskampagnen erstellen und ausführen. Am Beispiel der weltweit wichtigen Webseite ‚Stack Overflow‘ für Programmierer konnte (und kann) man sehen, wie der inflationäre Gebrauch von chatGPT aufgrund der inhärenten vielen Fehler dazu führt, dass das Management-Team von Stack Overflow seine Benutzer dringend bitten musste, den Einsatz von chatGPT komplett zu unterlassen, um den Zusammenbruch der Seite nach 14 Jahren zu verhindern. Im Falle von großen Playern, die es gezielt auf Desinformationen absehen, ist solch eine Maßnahme unwirksam. Diese Player zielen darauf ab, eine Datenwelt zu erschaffen, in der niemand mehr irgend jemandem vertrauen kann. Dies vor Augen stellt Gary Marcus 4 Postulate auf, die jede Gesellschaft umsetzen sollte: (1) Automatisch generierter Inhalt sollte komplett verboten werden; (2) Es müssen rechtswirksame Maßnahmen verabschiedet werden, die ‚Missinformationen‘ verhindern können; (3) User Accounts müssen fälschungssicher gemacht werden; (4) Es wird eine neue Generation von KI Werkzeugen gebraucht, die Fakten verifizieren können.
DER AUTOR
Einen Überblick über alle Beiträge von Autor cagent nach Titeln findet sich HIER.
