5.Aug 2023 – 29.Aug 2023 (10:37h)
Autor: Gerd Doeben-Henisch
Email: gerd@doeben-henisch.de
(Eine Englische Version findet sich hier: https://www.uffmm.org/2023/08/24/homo-sapiens-empirical-and-sustained-empirical-theories-emotions-and-machines-a-sketch/)
Kontext
Dieser Text stellt die Skizze zu einem Vortrag dar, der im Rahmen der Konferenz „KI – Text und Geltung. Wie verändern KI-Textgeneratoren wissenschaftliche Diskurse?“ (25./26.August 2023, TU Darmstadt) gehalten werden soll. [1] Die Englische Version des überarbeiteten Vortrags findet sich schon jetzt HIER: https://www.uffmm.org/2023/10/02/collective-human-machine-intelligence-and-text-generation-a-transdisciplinary-analysis/ . Die Deutsche Version des überarbeiteten Vortrags wird im Verlag Walter de Gruyter bis Ende 2023/ Anfang 2024 erscheinen. Diese Veröffentlichung wird hier dann bekannt gegeben werden.
Sehr geehrtes Auditorium,
In dieser Tagung mit dem Titel „KI – Text und Geltung. Wie verändern KI-Textgeneratoren wissenschaftliche Diskurse?“ geht es zentral um wissenschaftliche Diskurse und den möglichen Einfluss von KI-Textgeneratoren auf diese Diskurse. Der heiße Kern bleibt aber letztlich das Phänomen Text selbst, seine Geltung.
SICHTWEISEN-TRANS-DISZIPLINÄR
In dieser Konferenz werden zu diesem Thema viele verschiedene Sichten vorgetragen, die zu diesem Thema möglich sind.
Mein Beitrag zum Thema versucht die Rolle der sogenannten KI-Textgeneratoren dadurch zu bestimmen, dass aus einer ‚transdisziplinären Sicht‘ heraus die Eigenschaften von ‚KI-Textgeneratoren‘ in eine ’strukturelle Sicht‘ eingebettet werden, mit deren Hilfe die Besonderheiten von wissenschaftlichen Diskursen herausgestellt werden kann. Daraus können sich dann ‚Kriterien für eine erweiterte Einschätzung‘ von KI-Textgeneratoren in ihrer Rolle für wissenschaftliche Diskurse ergeben.
Einen zusätzlichen Aspekt bildet die Frage nach der Struktur der ‚kollektiven Intelligenz‘ am Beispiel des Menschen, und wie sich diese mit einer ‚Künstlichen Intelligenz‘ im Kontext wissenschaftlicher Diskurse möglicherweise vereinen kann.
‚Transdisziplinär‘ bedeutet in diesem Zusammenhang eine ‚Meta-Ebene‘ aufzuspannen, von der aus es möglich sein soll, die heutige ‚Vielfalt von Textproduktionen‘ auf eine Weise zu beschreiben, die ausdrucksstark genug ist, um eine ‚KI-basierte‘ Texterzeugung von einer ‚menschlichen‘ Texterzeugung unterscheiden zu können.
MENSCHLICHE TEXTERZEUGUNG
Die Formulierung ‚wissenschaftlicher Diskurs‘ ist ein Spezialfall des allgemeineren Konzepts ‚menschliche Texterzeugung‘.
Dieser Perspektivenwechsel ist meta-theoretisch notwendig, da es auf den ersten Blick nicht der ‚Text als solcher ‚ ist, der über ‚Geltung und Nicht-Geltung‘ entscheidet, sondern die ‚Akteure‘, die ‚Texte erzeugen und verstehen‘. Und beim Auftreten von ‚verschiedenen Arten von Akteuren‘ — hier ‚Menschen‘, dort ‚Maschinen‘ — wird man nicht umhin kommen, genau jene Unterschiede — falls vorhanden — zu thematisieren, die eine gewichtige Rolle spielen bei der ‚Geltung von Texten‘.
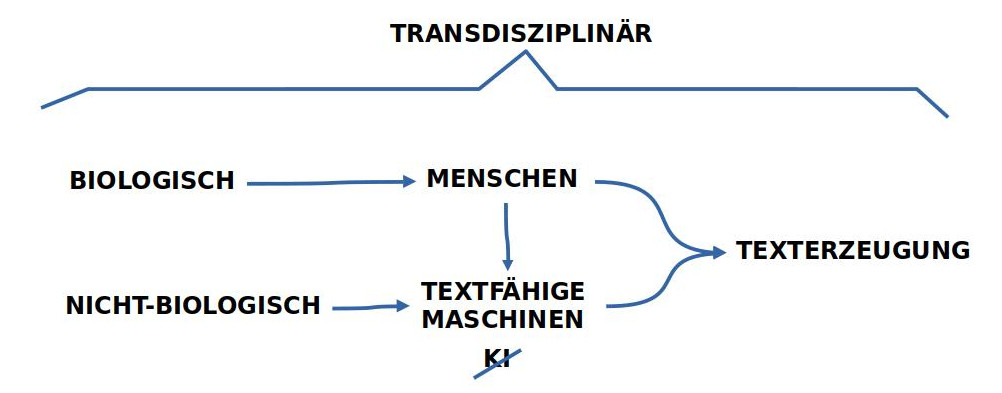
TEXTFÄHIGE MASCHINEN
Bei der Unterscheidung in zwei verschiedenen Arten von Akteuren — hier ‚Menschen‘, dort ‚Maschinen‘ — sticht sofort eine erste ‚grundlegende Asymmetrie‘ ins Auge: sogenannte ‚KI-Textgeneratoren‘ sind Gebilde, die von Menschen ‚erfunden‘ und ‚gebaut‘ wurden, es sind ferner Menschen, die sie ‚benutzen‘, und das wesentliche Material, das von sogenannten KI-Generatoren benutzt wird, sind wiederum ‚Texte‘, die als ‚menschliches Kulturgut‘ gelten.
Im Falle von sogenannten ‚KI-Textgeneratoren‘ soll hier zunächst nur so viel festgehalten werden, dass wir es mit ‚Maschinen‘ zu tun haben, die über ‚Input‘ und ‚Output‘ verfügen, dazu über eine minimale ‚Lernfähigkeit‘, und deren Input und Output ‚textähnliche Objekte‘ verarbeiten kann.
BIOLOGISCH-NICHT-BIOLOGISCH
Auf der Meta-Ebene wird also angenommen, dass wir einerseits über solche Akteure verfügen, die minimal ‚textfähige Maschinen‘ sind — durch und durch menschliche Produkte –, und auf der anderen Seite über Akteure, die wir ‚Menschen‘ nennen. Menschen gehören als ‚Homo-Sapiens Population‘ zur Menge der ‚biologischen Systeme‘, während ‚textfähige Maschinen‘ zu den ’nicht-biologischen Systemen‘ gehören.
LEERSTELLE INTELLIGENZ-BEGRIFF
Die hier vorgenommene Transformation des Begriffs ‚KI-Textgenerator‘ in den Begriff ‚textfähige Maschine‘ soll zusätzlich verdeutlichen, dass die verbreitete Verwendung des Begriffs ‚KI‘ für ‚Künstliche Intelligenz‘ eher irreführend ist. Es gibt bislang in keiner wissenschaftlichen Disziplin einen allgemeinen, über die Einzeldisziplin hinaus anwendbaren und akzeptierten Begriff von ‚Intelligenz‘. Für die heute geradezu inflatorische Verwendung des Begriffs KI gibt es keine wirkliche Begründung außer jener, dass der Begriff so seiner Bedeutung entleert wurde, dass man ihn jederzeit und überall benutzen kann, ohne etwas Falsches zu sagen. Etwas, was keine Bedeutung besitzt, kann weder wahr‘ noch ‚falsch‘ sein.
VORAUSSETZUNGEN FÜR TEXT-GENERIERUNG
Wenn nun die Homo-Sapiens Population als originärer Akteur für ‚Text-Generierung‘ und ‚Text-Verstehen‘ identifiziert wird, soll nun zunächst untersucht werden, welches denn ‚jene besonderen Eigenschaften‘ sind, die eine Homo-Sapiens Population dazu befähigt, Texte zu generieren und zu verstehen und sie ‚im alltäglichen Lebensprozess erfolgreich anzuwenden‘.
GELTUNG
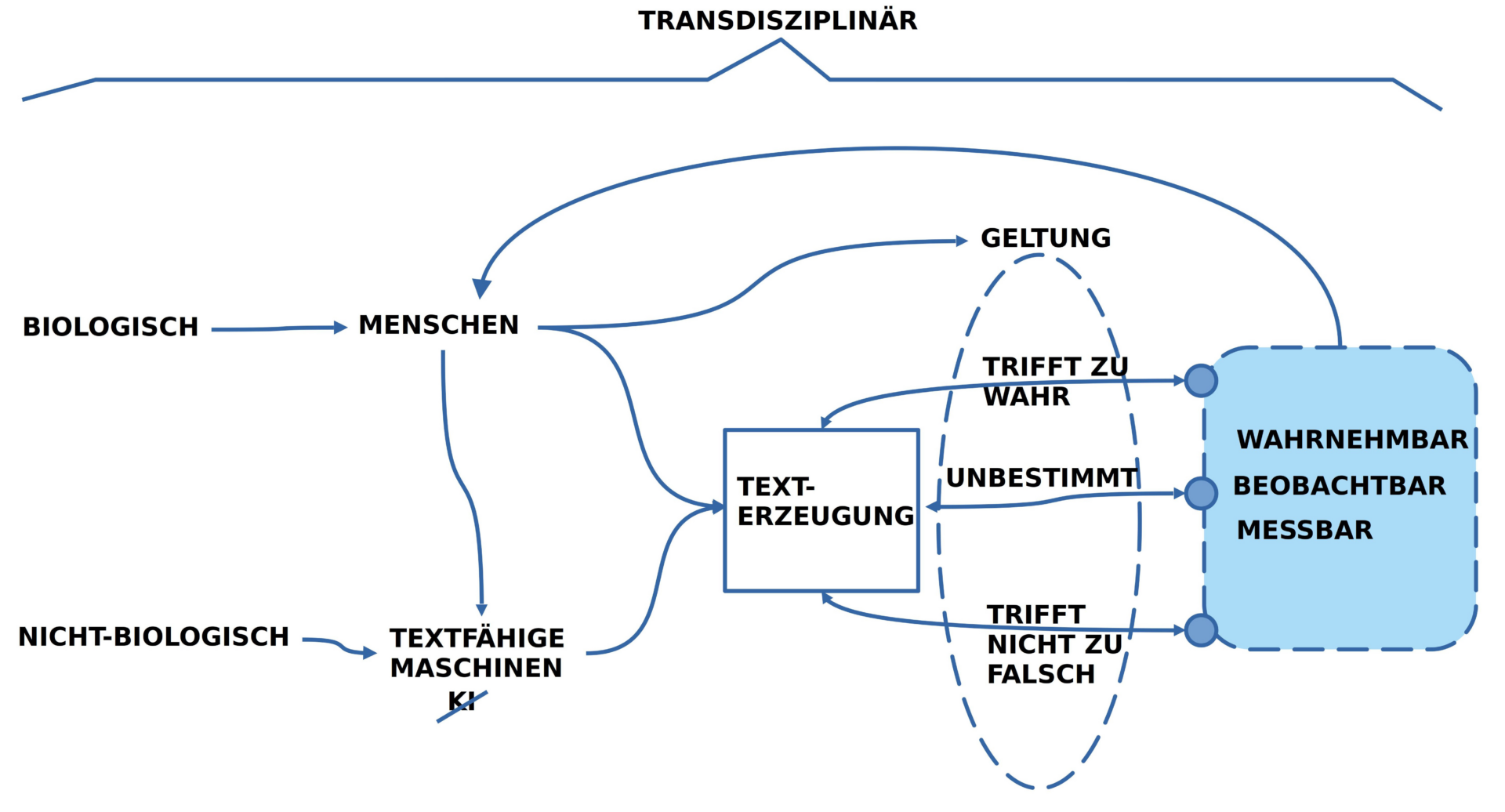
Ein Anknüpfungspunkt für die Untersuchung der besonderen Eigenschaften einer Homo-Sapiens Text-Generierung und eines Text-Verstehens ist der Begriff ‚Geltung‘, der im Tagungsthema vorkommt.
Auf dem primären Schauplatz des biologischen Lebens, in den alltäglichen Prozessen, im Alltag, hat die ‚Geltung‘ eines Textes mit ‚Zutreffen‘ zu tun. Wenn ein Text nicht von vornherein mit einem ‚fiktiven Charakter‘ geplant wird, sondern mit einem ‚Bezug zum Alltagsgeschehen‘, das jeder im Rahmen seiner ‚Weltwahrnehmung‘ ‚überprüfen‘ kann, dann hat ‚Geltung im Alltag‘ damit zu tun, dass das ‚Zutreffen eines Textes überprüft‘ werden kann. Trifft die ‚Aussage eines Textes‘ im Alltag ‚zu‘, dann sagt man auch, dass diese Aussage ‚gilt‘, man räumt ihr ‚Geltung‘ ein, man bezeichnet sie auch als ‚wahr‘. Vor diesem Hintergrund könnte man geneigt sein fortzusetzen und zu sagen: ‚Trifft‘ die Aussage eines Textes ’nicht zu‘, dann kommt ihr ‚keine Geltung‘ zu; vereinfacht zur Formulierung, dass die Aussage ’nicht wahr‘ sei bzw. schlicht ‚falsch‘.
Im ‚realen Alltag‘ ist die Welt allerdings selten ’schwarz‘ und ‚weiß‘: nicht selten kommt es vor, dass wir mit Texten konfrontiert werden, denen wir aufgrund ihrer ‚gelernten Bedeutung‘ geneigt sind ‚eine mögliche Geltung‘ zu zuschreiben, obwohl es möglicherweise gar nicht klar ist, ob es eine Situation im Alltag gibt — bzw. geben wird –, in der die Aussage des Textes tatsächlich zutrifft. In solch einem Fall wäre die Geltung dann ‚unbestimmt‘; die Aussage wäre ‚weder wahr noch falsch‘.
ASYMMETRIE: ZUTREFFEN – NICHT-ZUTREFFEN
Man kann hier eine gewisse Asymmetrie erkennen: Das ‚Zutreffen‘ einer Aussage, ihre tatsächliche Geltung, ist vergleichsweise eindeutig. Das ‚Nicht-Zutreffen‘, also eine ‚bloß mögliche‘ Geltung, ist hingegen schwierig zu entscheiden.
Wir berühren mit diesem Phänomen der ‚aktuellen Nicht-Entscheidbarkeit‘ einer Aussage sowohl das Problem der ‚Bedeutung‘ einer Aussage — wie weit ist überhaupt klar, was gemeint ist? — als auch das Problem der ‚Unabgeschlossenheit unsres Alltags‘, besser bekannt als ‚Zukunft‘: ob eine ‚aktuelle Gegenwart‘ sich als solche fortsetzt, ob genau so, oder ob ganz anders, das hängt davon ab, wie wir ‚Zukunft‘ generell verstehen und einschätzen; was die einen als ’selbstverständlich‘ für eine mögliche Zukunft annehmen, kann für die anderen schlicht ‚Unsinn‘ sein.
BEDEUTUNG
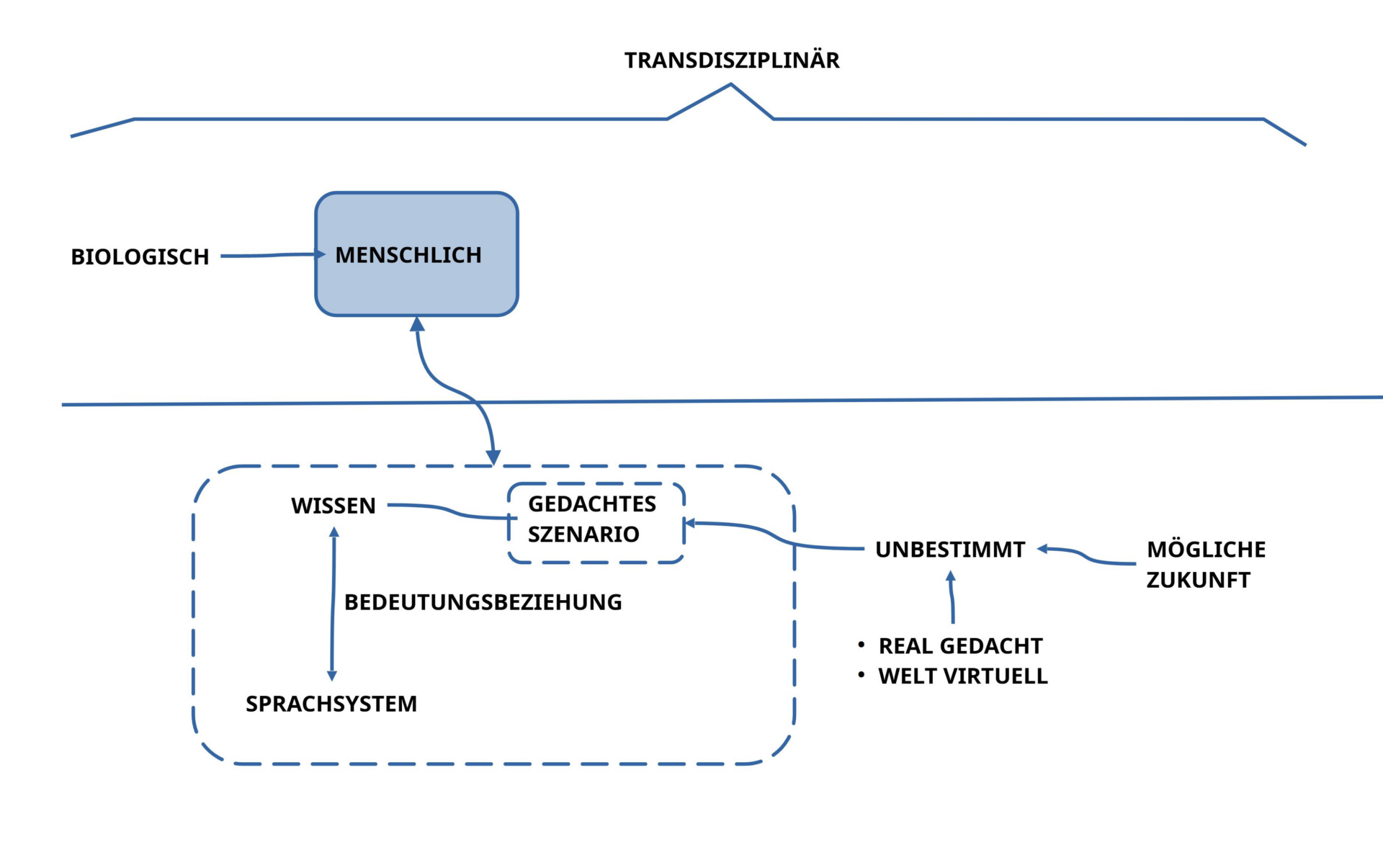
Dieses Spannungsfeld von ‚aktuell entscheidbar‘ und ‚aktuell noch nicht entscheidbar‘ verdeutlicht zusätzlich einen ‚autonomen‘ Aspekt des Phänomens Bedeutung: hat sich ein bestimmtes Wissen im Gehirn gebildet und wurde dieses als ‚Bedeutung‘ für ein ‚Sprachsystem‘ nutzbar gemacht, dann gewinnt diese ‚assoziierte‘ Bedeutung für den Geltungsbereich des Wissens eine eigene ‚Realität‘: es ist nicht die ‚Realität jenseits des Gehirns‘, sondern die ‚Realität des eigenen Denkens‘, wobei diese Realität des Denkens ‚von außen betrachtet‘ etwas ‚Virtuelles‘ hat.
Will man über diese ‚besondere Realität der Bedeutung‘ im Kontext des ‚ganzen Systems‘ sprechen, dann muss man zu weitreichenden Annahmen greifen, um auf der Meta-Ebene einen ‚begrifflichen Rahmen‘ installieren zu können, der in der Lage ist, die Struktur und die Funktion von Bedeutung hinreichend beschreiben zu können. Dafür werden minimal die folgenden Komponenten angenommen (‚Wissen‘, ‚Sprache‘ sowie ‚Bedeutungsbeziehung‘):
- WISSEN: Es gibt die Gesamtheit des ‚Wissens‘, das sich im Homo-Sapiens Akteur im Laufe der Zeit im Gehirn ‚aufbaut‘: sowohl aufgrund von kontinuierlichen Interaktionen des ‚Gehirns‘ mit der ‚Umgebung des Körpers‘, als auch aufgrund von Interaktionen ‚mit dem Körper selbst‘, sowie auch aufgrund der Interaktionen ‚des Gehirns mit sich selbst‘.
- SPRACHE: Vom Wissen zu unterscheiden ist das dynamische System der ‚potentiellen Ausdrucksmittel‘, hier vereinfachend ‚Sprache‘ genannt, die sich im Laufe der Zeit in Interaktion mit dem ‚Wissen‘ entfalten können.
- BEDEUTUNGSBEZIEHUNG: Schließlich gibt es die dynamische ‚Bedeutungsbeziehung‘, ein Interaktionsmechanismus, der beliebige Wissenselemente jederzeit mit beliebigen sprachlichen Ausdrucksmitteln verknüpfen kann.
Jede dieser genannten Komponenten ‚Wissen‘, ‚Sprache‘ wie auch ‚Bedeutungsbeziehung‘ ist extrem komplex; nicht weniger komplex ist auch ihr Zusammenspiel.
ZUKUNFT UND EMOTIONEN
Neben dem Phänomen Bedeutung wurde beim Phänomen des Zutreffens auch sichtbar, dass die Entscheidung des Zutreffens auch von einer ‚verfügbaren Alltagssituation‘ abhängt, in der sich eine aktuelle Entsprechung ‚konkret aufzeigen‘ lässt oder eben nicht.
Verfügen wir zusätzlich zu einer ‚denkbaren Bedeutung‘ im Kopf aktuell über keine Alltagssituation, die dieser Bedeutung im Kopf hinreichend korrespondiert, dann gibt es immer zwei Möglichkeiten: Wir können diesem gedachten Konstrukt trotz fehlendem Realitätsbezug den ‚Status einer möglichen Zukunft‘ verleihen oder nicht.
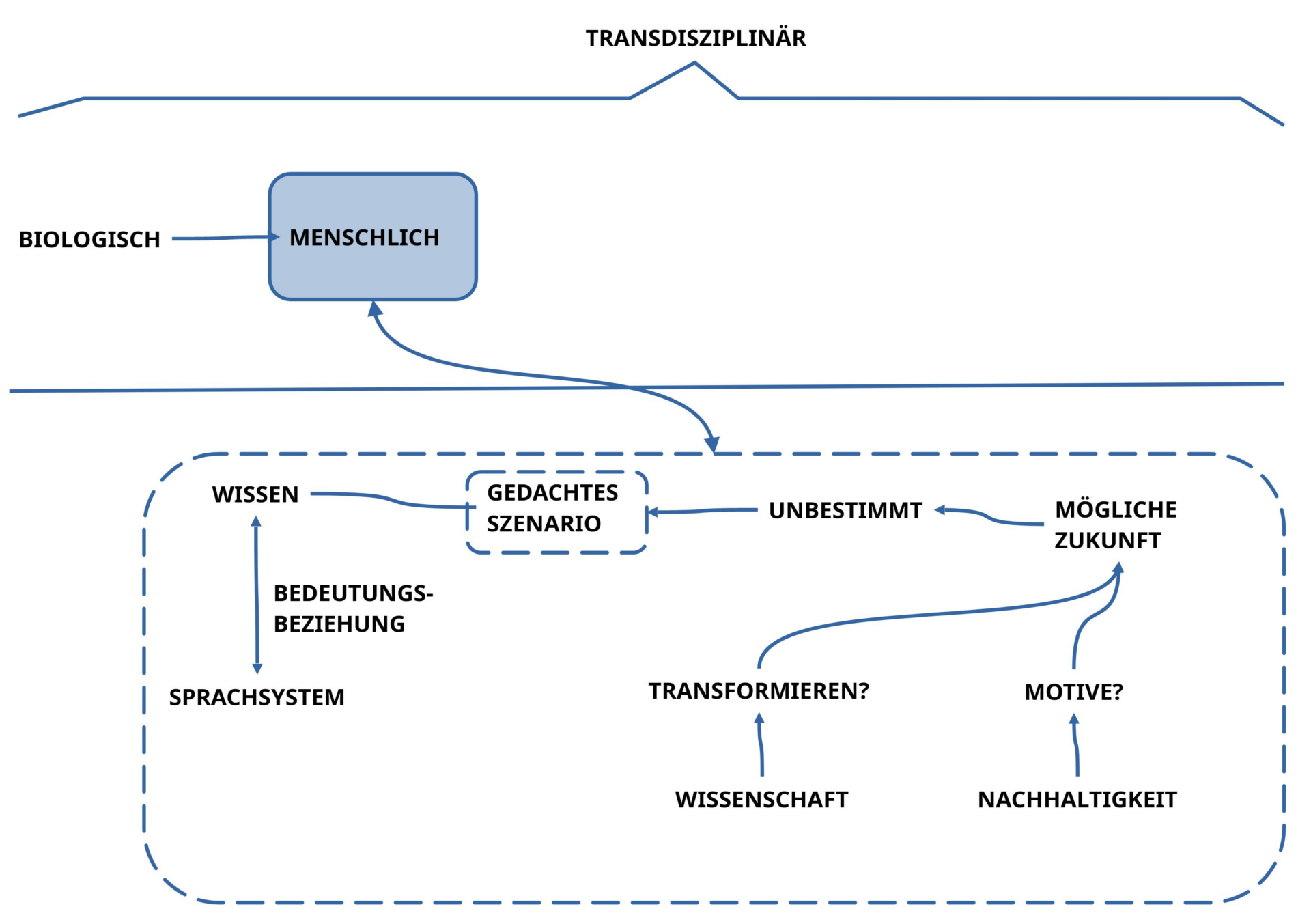
Würden wir uns dafür entscheiden, einer ‚Bedeutung im Kopf‘ den Status einer möglichen Zukunft zu zusprechen, dann stehen meistens folgende zwei Anforderungen im Raum: (i) Lässt sich im Lichte des verfügbaren Wissens hinreichend plausibel machen, dass sich die ‚gedachte mögliche Situation‘ in ‚absehbarer Zeit‘ ausgehend von der aktuellen realen Situation ‚in eine neue reale Situation transformieren lässt‘? Und (ii) Gibt es ’nachhaltige Gründe‚ warum man diese mögliche Zukunft ‚wollen und bejahen‘ sollte?
Die erste Forderung verlangt nach einer leistungsfähigen ‚Wissenschaft‘, die aufhellt, ob es überhaupt gehen kann. Die zweite Forderung geht darüber hinaus und bringt unter dem Gewand der ‚Nachhaltigkeit‘ den scheinbar ‚irrationalen‘ Aspekt der ‚Emotionalität‘ ins Spiel: es geht nicht nur einfach um ‚Wissen als solches‘, es geht auch nicht nur um ein ’sogenanntes nachhaltiges Wissen‘, das dazu beitragen soll, das Überleben des Lebens auf dem Planet Erde — und auch darüber hinaus — zu unterstützen, es geht vielmehr auch um ein ‚gut finden, etwas bejahen, und es dann auch entscheiden wollen‘. Diese letzten Aspekte werden bislang eher jenseits von ‚Rationalität‘ angesiedelt; sie werden dem diffusen Bereich der ‚Emotionen‘ zugeordnet; was seltsam ist, da ja jedwede Form von ‚üblicher Rationalität‘ genau in diesen ‚Emotionen‘ gründet.[2]
WISSENSCHAFTLICHER DISKURS UND ALLTAGSSITUATIONEN
In diesem soeben angedeuteten Kontext von ‚Rationalität‘ und ‚Emotionalität‘ ist es nicht uninteressant, dass im Tagungsthema der ‚wissenschaftliche Diskurs‘ als Referenzpunkt thematisiert wird, um den Stellenwert textfähiger Maschinen abzuklären.
Es fragt sich, inwieweit ein ‚wissenschaftlicher Diskurs‘ überhaupt als Referenzpunkt für einen erfolgreichen Text dienen kann?
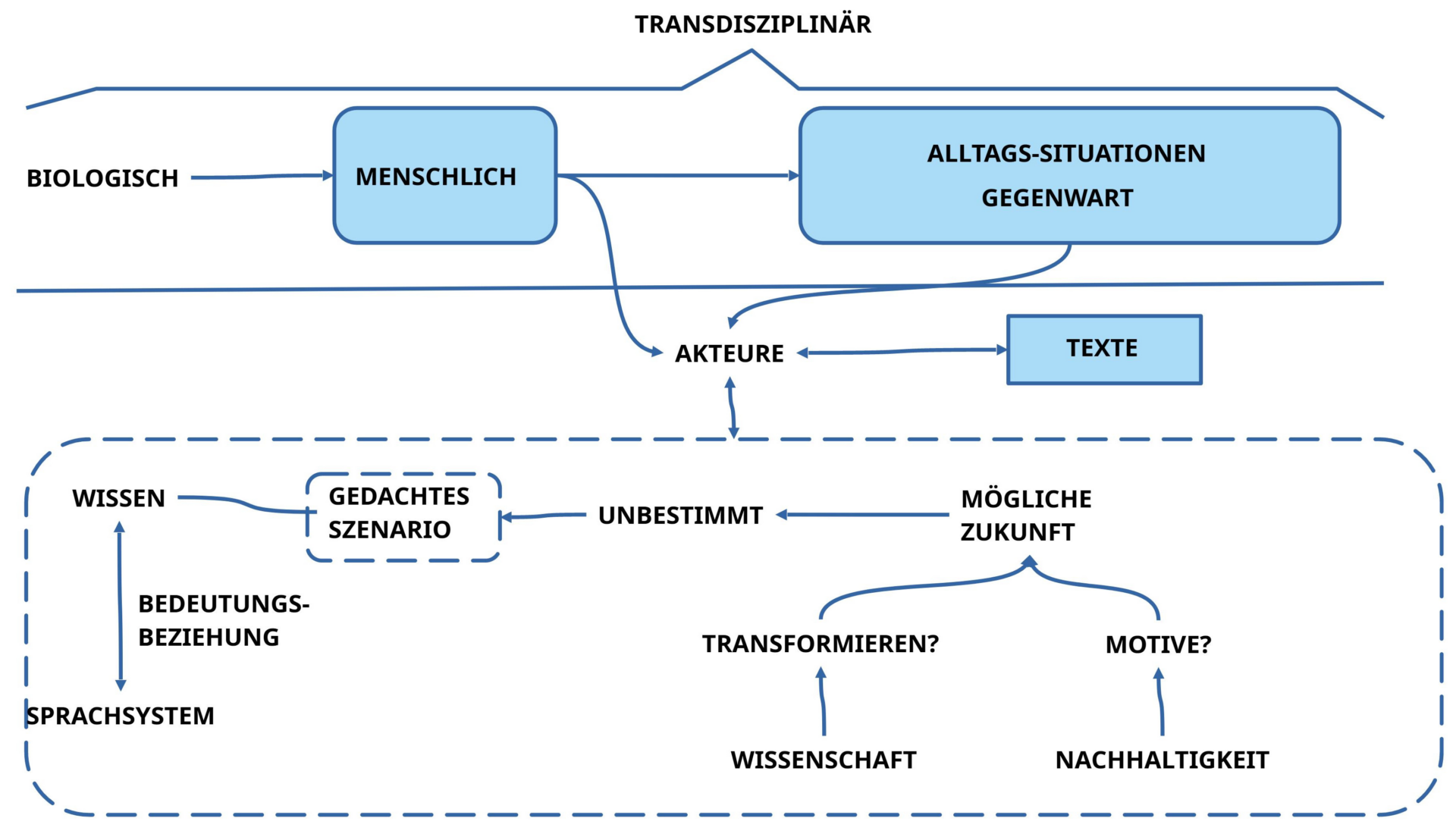
Dazu kann es helfen, sich bewusst zu machen, dass das Leben auf diesem Planet Erde sich in jedem Moment in einer unfassbar großen Menge von ‚Alltagssituationen‘ abspielt, die alle gleichzeitig stattfinden. Jede ‚Alltagssituation‘ repräsentiert für die Akteure eine ‚Gegenwart‘. Und in den Köpfen der Akteure findet sich ein individuell unterschiedliches Wissen darüber, wie sich eine Gegenwart in einer möglichen Zukunft ‚verändern kann‘ bzw. verändern wird.
Dieses ‚Wissen in den Köpfen‘ der beteiligten Akteure kann man generell ‚in Texte transformieren‘, die auf unterschiedliche Weise einige der Aspekte des Alltags ’sprachlich repräsentieren‘.
Der entscheidende Punkt ist, dass es nicht ausreicht, dass jeder ‚für sich‘ alleine, ganz ‚individuell‘, einen Text erzeugt, sondern dass jeder zusammen ‚mit allen anderen‘, die auch von der Alltagssituation betroffen sind, einen ‚gemeinsamen Text‘ erzeugen muss. Eine ‚kollektive‘ Leistung ist gefragt.
Und es geht auch nicht um ‚irgendeinen‘ Text, sondern um einen solchen, der so beschaffen ist, dass er die ‚Generierung möglicher Fortsetzungen in der Zukunft‘ erlaubt, also das, was traditionell von einem ‚wissenschaftlichen Text‘ erwartet wird.
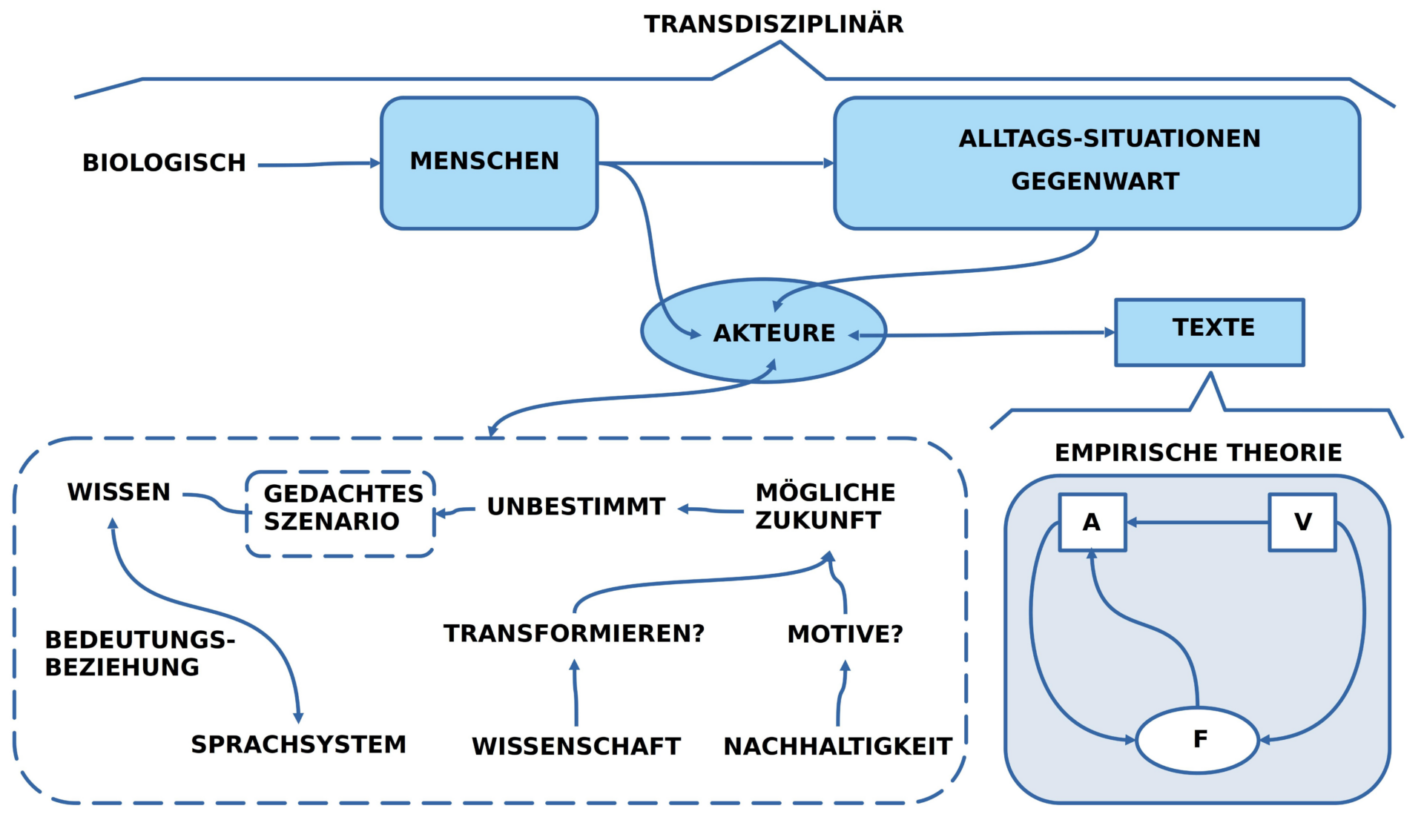
Aus der umfangreichen Diskussion — seit den Zeiten eines Aristoteles — was denn ‚wissenschaftlich‘ bedeuten soll, was eine ‚Theorie‘ ist, was eine ‚empirische Theorie‘ sein soll, skizziere ich das, was ich hier das ‚minimale Konzept einer empirischen Theorie‘ nenne.
- Ausgangspunkt ist eine ‚Gruppe von Menschen‘ (die ‚Autoren‘), die einen ‚gemeinsamen Text‘ erstellen wollen.
- Dieser Text soll die Eigenschaft besitzen, dass er ‚begründbare Voraussagen‘ für mögliche ‚zukünftige Situationen‘ erlaubt, denen sich dann in der Zukunft ‚irgendwann‘ auch eine ‚Geltung zuordnen lässt‘.
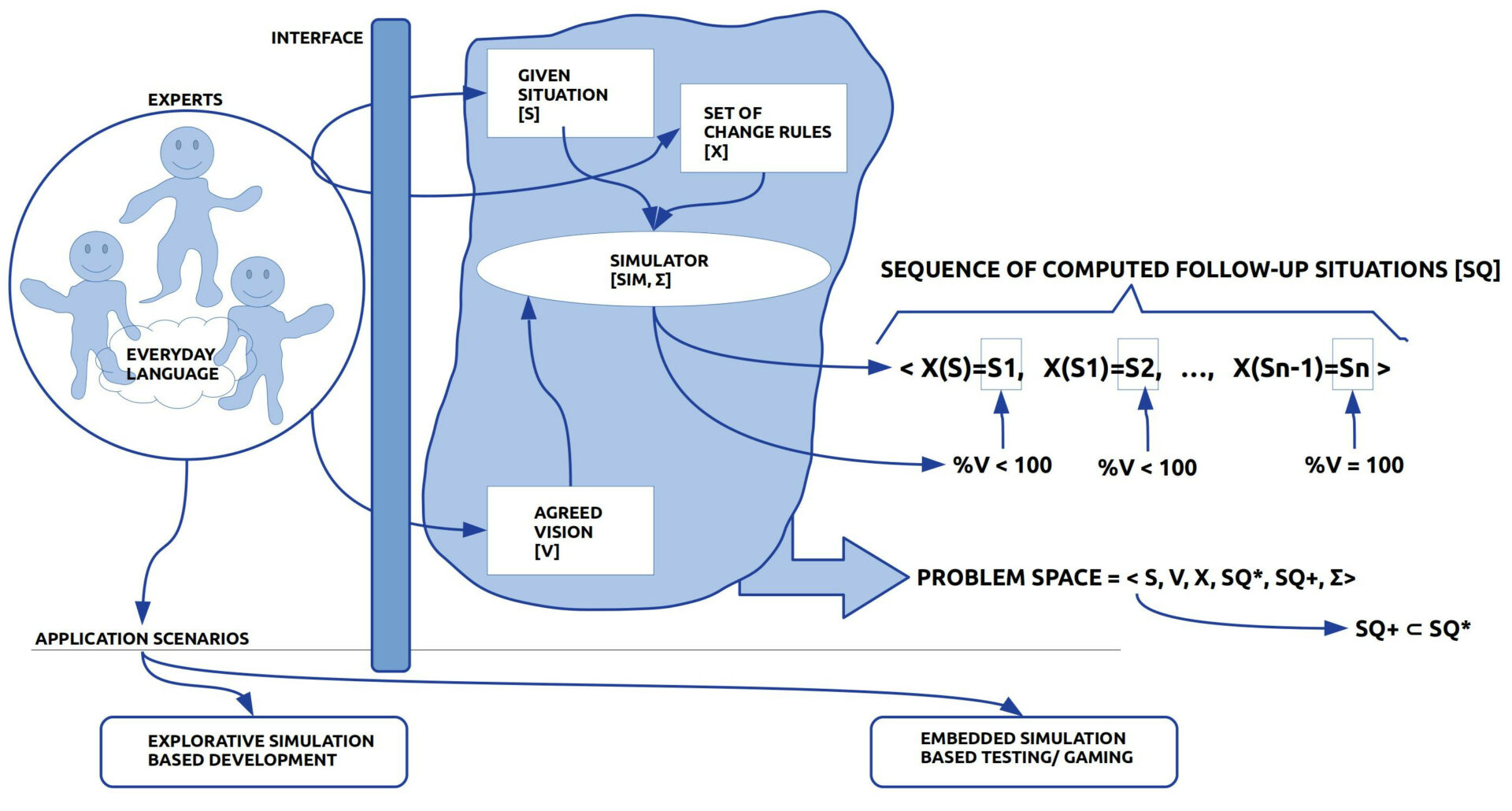
- Die Autoren sind in der Lage, sich auf eine ‚Ausgangssituation‘ zu einigen, die sie mittels einer ‚gemeinsamen Sprache‘ in einen ‚Ausgangstext‘ [A] transformieren.
- Es gilt als abgemacht, dass dieser Ausgangstext nur ’solche sprachliche Ausdrücke‘ enthalten darf, die sich ‚in der Ausgangssituation‘ als ‚wahr‘ ausweisen lassen.
- In einem weiteren Text stellen die Autoren eine Reihe von ‚Veränderungsregeln‘ [V] zusammen, die ‚Formen von Veränderungen‘ an einer gegebenen Situation ins Wort bringen.
- Auch in diesem Fall gilt es als abgemacht, dass nur ’solche Veränderungsregeln‘ aufgeschrieben werden dürfen, von denen alle Autoren wissen, dass sie sich in ‚vorausgehenden Alltagssituationen‘ als ‚wahr‘ erwiesen haben.
- Der Text mit den Veränderungsregeln V liegt auf einer ‚Meta-Ebene‘ verglichen mit dem Text A über die Ausgangssituation, der relativ zum Text V auf einer ‚Objekt-Ebene‘ liegt.
- Das ‚Zusammenspiel‘ zwischen dem Text V mit den Veränderungsregeln und dem Text A mit der Ausgangssituation wird in einem eigenen ‚Anwendungstext‘ [F] beschrieben: Hier wird beschrieben, wann und wie man eine Veränderungsregel (in V) auf einen Ausgangstext A anwenden darf und wie sich dabei der ‚Ausgangstext A‘ zu einem ‚Folgetext A*‘ verändert.
- Der Anwendungstext F liegt damit auf einer nächst höheren Meta-Ebene zu den beiden Texten A und V und kann bewirken, dass der Anwendungstext den Ausgangstext A verändert wird.
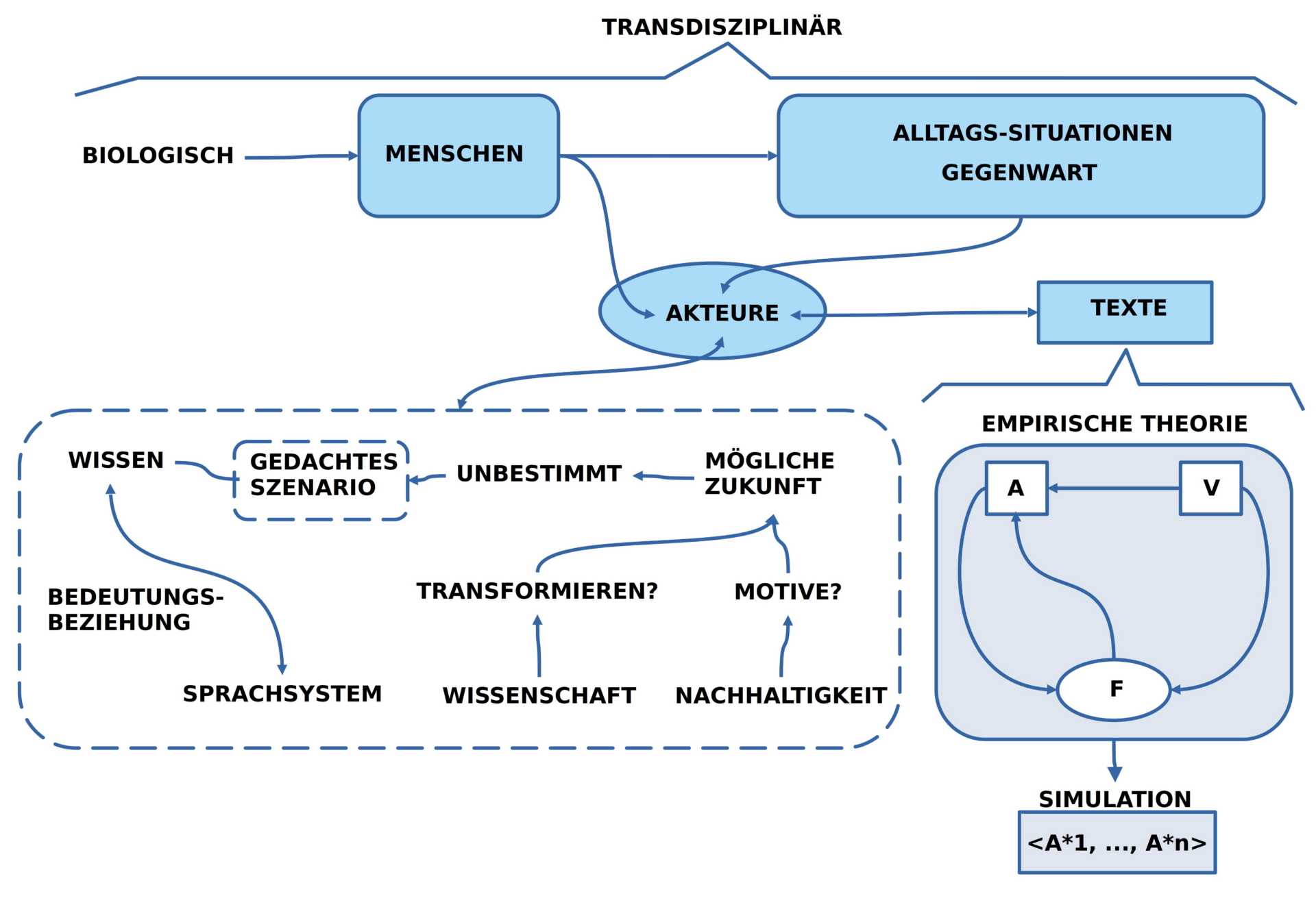
- In dem Moment, wo ein neuer Folgetext A* vorliegt, wird der Folgetext A* zum neuen Anfangstext A.
- Falls der neue Ausgangstext A so beschaffen ist, dass sich wieder eine Veränderungsregel aus V anwenden lässt, dann wiederholt sich die Erzeugung eines neuen Folgetextes A*.
- Diese ‚Wiederholbarkeit‘ der Anwendung kann zur Generierung von vielen Folgetexten <A*1, …, A*n> führen.
- Eine Serie von vielen Folgetexten <A*1, …, A*n> nennt man üblicherweise auch eine ‚Simulation‘.
- Abhängig von der Beschaffenheit des Ausgangstextes A und der Art der Veränderungsregeln in V kann es sein, dass mögliche Simulationen ‚ganz unterschiedlich verlaufen können‘. Die Menge der möglichen wissenschaftlichen Simulationen repräsentiert ‚Zukunft‘ damit also nicht als einen einzigen, bestimmten Verlauf, sondern als eine ‚beliebig große Menge möglicher Verläufe‘.
- Die Faktoren, von denen unterschiedliche Verläufe abhängen, sind vielfältig. Ein Faktor sind die Autoren selbst. Jeder Autor ist ja mit seiner Körperlichkeit vollständig selbst Teil genau jener empirischen Welt, die in einer wissenschaftlichen Theorie beschrieben werden soll. Und wie bekannt, kann jeder menschliche Akteur seine Meinung jederzeit ändern. Er kann buchstäblich im nächsten Moment genau das Gegenteil von dem tun, was er zuvor gedacht hat. Und damit ist die Welt schon nicht mehr die gleiche, wie zuvor in der wissenschaftlichen Beschreibung angenommen.
Schon dieses einfache Beispiel zeigt, dass die Emotionalität des ‚Gut-Findens, des Wollens, und des Entscheidens‘ der Rationalität wissenschaftlicher Theorien voraus liegt. Dies setzt sich in der sogenannten ‚Nachhaltigkeitsdiskussion‘ fort.
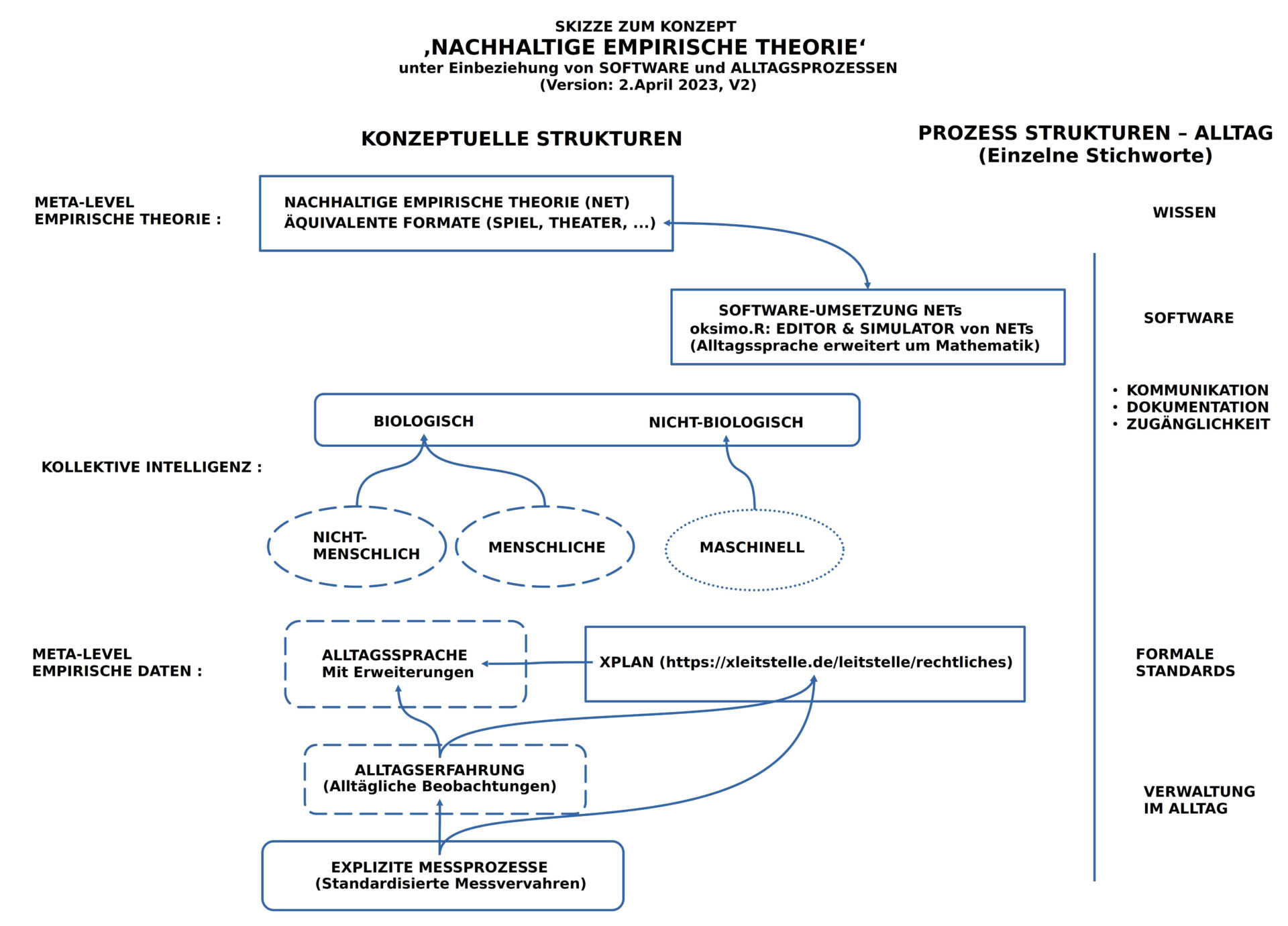
NACHHALTIGE EMPIRISCHE THEORIE
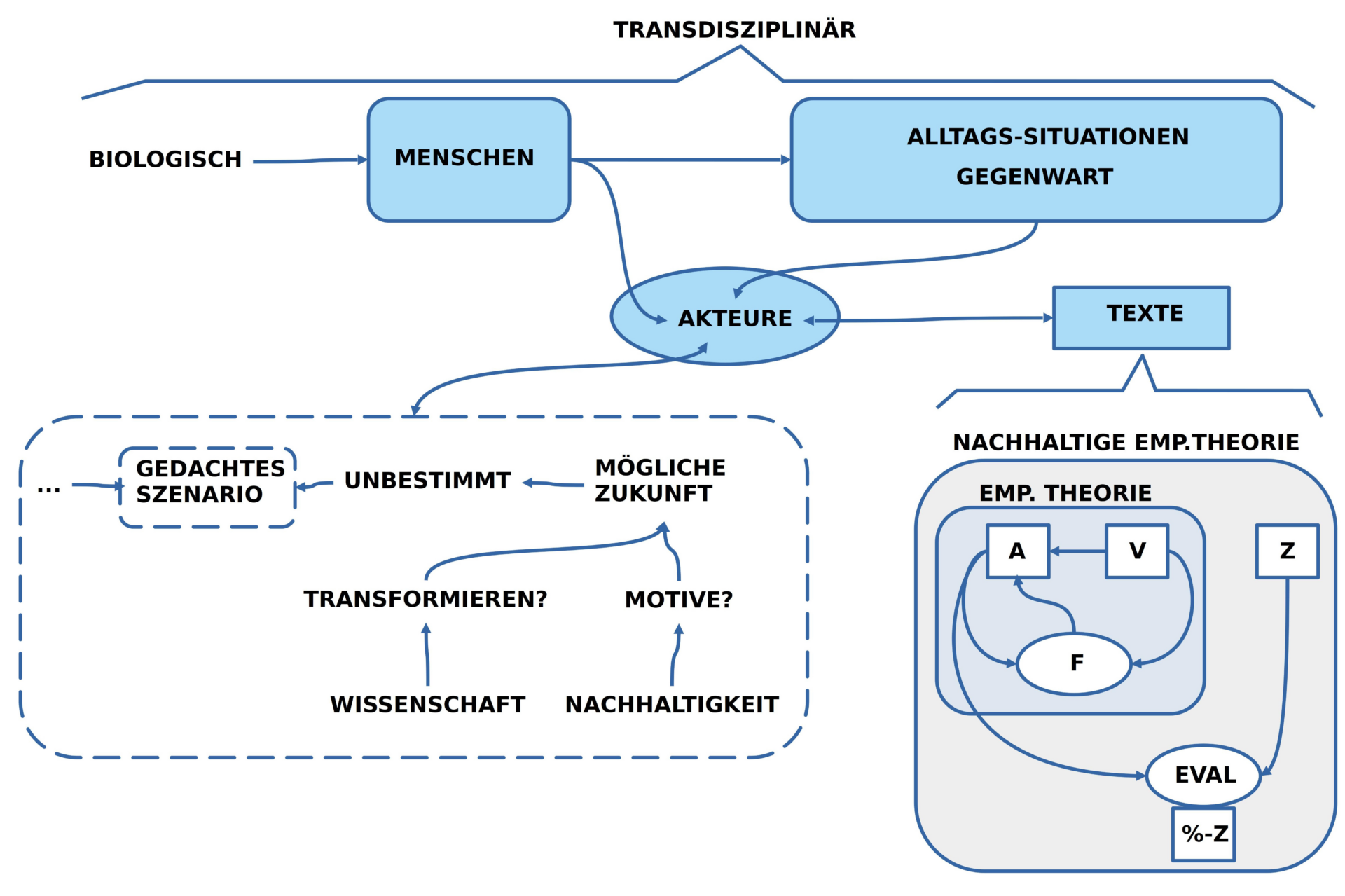
Mit dem soeben eingeführten ‚minimalen Konzepts einer empirischen Theorie (ET)‘ lässt sich direkt auch ein ‚minimales Konzept einer nachhaltigen empirischen Theorie (NET)‘ einführen.
Während eine empirische Theorie einen beliebig großen Raum an begründeten Simulationen aufspannen kann, die den Raum von vielen möglichen Zukünften sichtbar machen, verbleibt den Akteuren des Alltags die Frage, was sie denn von all dem als ‚ihre Zukunft‘ haben wollen? In der Gegenwart erleben wir die Situation, dass die Menschheit den Eindruck erweckt, als ob sie damit einverstanden ist, das Leben jenseits der menschlichen Population mehr und mehr nachhaltig zu zerstören mit dem erwartbaren Effekt der ‚Selbst-Zerstörung‘.
Dieser in Umrissen vorhersehbare Selbst-Zerstörungseffekt ist aber im Raum der möglichen Zukünfte nur eine Variante. Die empirische Wissenschaft kann sie umrisshaft andeuten. Diese Variante vor anderen auszuzeichnen, sie als ‚gut‘ zu akzeptieren, sie ‚zu wollen‘, sich für diese Variante zu ‚entscheiden‘, liegt in jenem bislang kaum erforschten Bereich der Emotionalität als Wurzel aller Rationalität.
Wenn sich Akteure des Alltags für eine bestimmte rational aufgehellte Variante von möglicher Zukunft entschieden haben, dann können sie jederzeit mit einem geeigneten ‚Evaluationsverfahren (EVAL)‘ auswerten, wie viel ‚Prozent (%) der Eigenschaften des Zielzustandes Z‘ bislang erreicht worden sind, vorausgesetzt, der favorisierte Zielzustand wird in einen passenden Text Z transformiert.
Anders formuliert: in dem Moment, wo wir Alltagsszenarien über geeignete Texte in einen rational greifbaren Zustand transformiert haben, nehmen die Dinge eine gewisse Klarheit an und werden dadurch — in gewisser Weise — einfach. Dass wir solche Transformationen vornehmen und auf welche Aspekte eines realen oder möglichen Zustands wir uns dann fokussieren, das ist aber als emotionale Dimension der textbasierten Rationalität vor-gelagert.[2]
MENSCH-MASCHINE
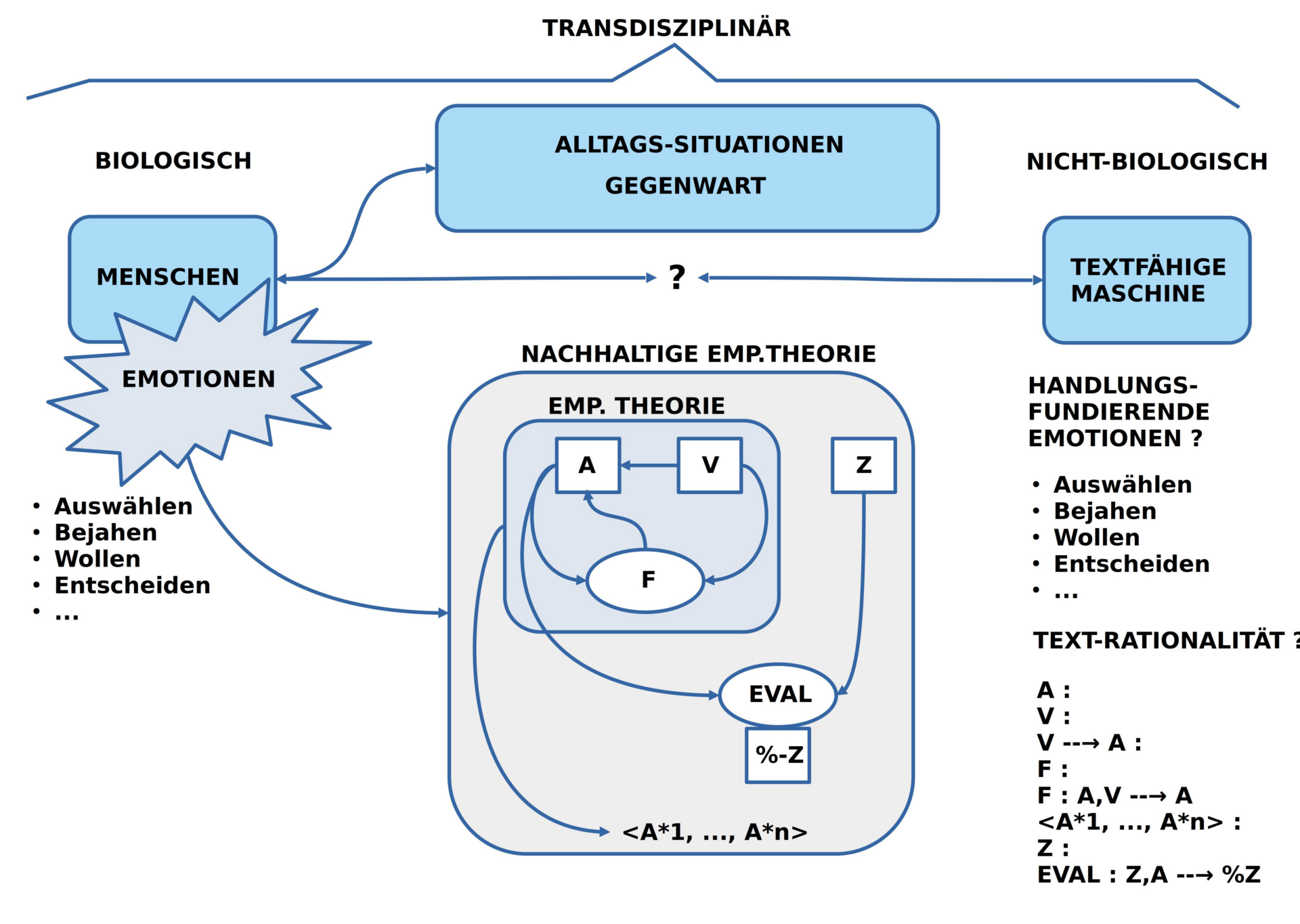
Nach diesen vorbereitenden Überlegungen stellt sich die abschließende Frage, ob und wie die Hauptfrage dieser Tagung „Wie verändern KI-Textgeneratoren wissenschaftliche Diskurse?“ in irgendeiner Weise beantwortet werden kann?
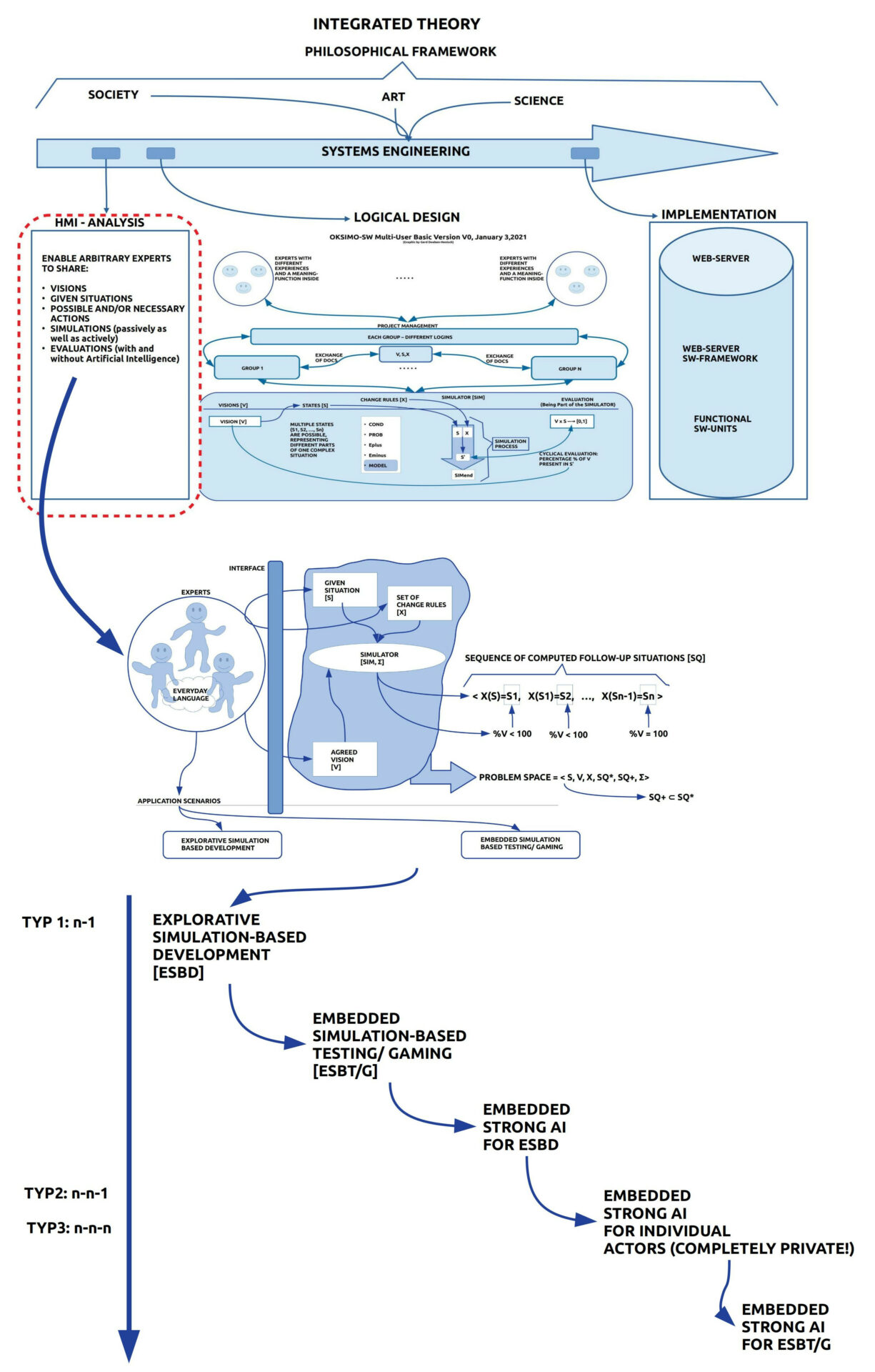
Meine bisherigen Ausführungen haben versucht aufzuzeigen, was es bedeutet, dass Menschen kollektiv Texte erzeugen, die die Kriterien für einen wissenschaftlichen Diskurs erfüllen, der zudem die Anforderungen für empirische oder gar nachhaltig-empirische Theorien erfüllt.
Dabei zeigt sich, dass sowohl bei der Generierung eines kollektiven wissenschaftlichen Textes wie auch bei seiner Anwendung im Alltag ein enger Wechselbezug sowohl mit der gemeinsamen erfahrbaren Welt wie auch mit den dynamischen Wissens- und Bedeutungskomponenten in jedem Akteur eine Rolle spielen.
Der Aspekt der ‚Geltung‘ ist Teil eines dynamischen Weltbezugs, dessen Einschätzung als ‚wahr‘ beständig im Fluss ist; während der eine Akteur vielleicht dazu tendiert zu sagen „Ja, kann stimmen“, tendiert ein anderer Akteur vielleicht gerade zum Gegenteil. Während die einen eher dazu tendieren, eine mögliche Zukunftsvariante X zu favorisieren, wollen die anderen lieber die Zukunftsvariante Y. Rationale Argumente fehlen; die Gefühle sprechen. Während eine Gruppe gerade beschlossen hat, dem Plan Z zu ‚glauben‘ und ihn ‚umzusetzen‘, wenden sich die anderen ab, verwerfen Plan Z, und tun etwas ganz anderes.
Dieser unstete, unsichere Charakter des Zukunft-Deutens und Zukunft-Handelns begleitet die Homo Sapiens Population von Anbeginn. Der unverstandene emotionale Komplex begleitet den Alltag beständig wie ein Schatten.[2]
Wo und wie können ‚textfähige Maschinen‘ in dieser Situation einen konstruktiven Beitrag leisten?
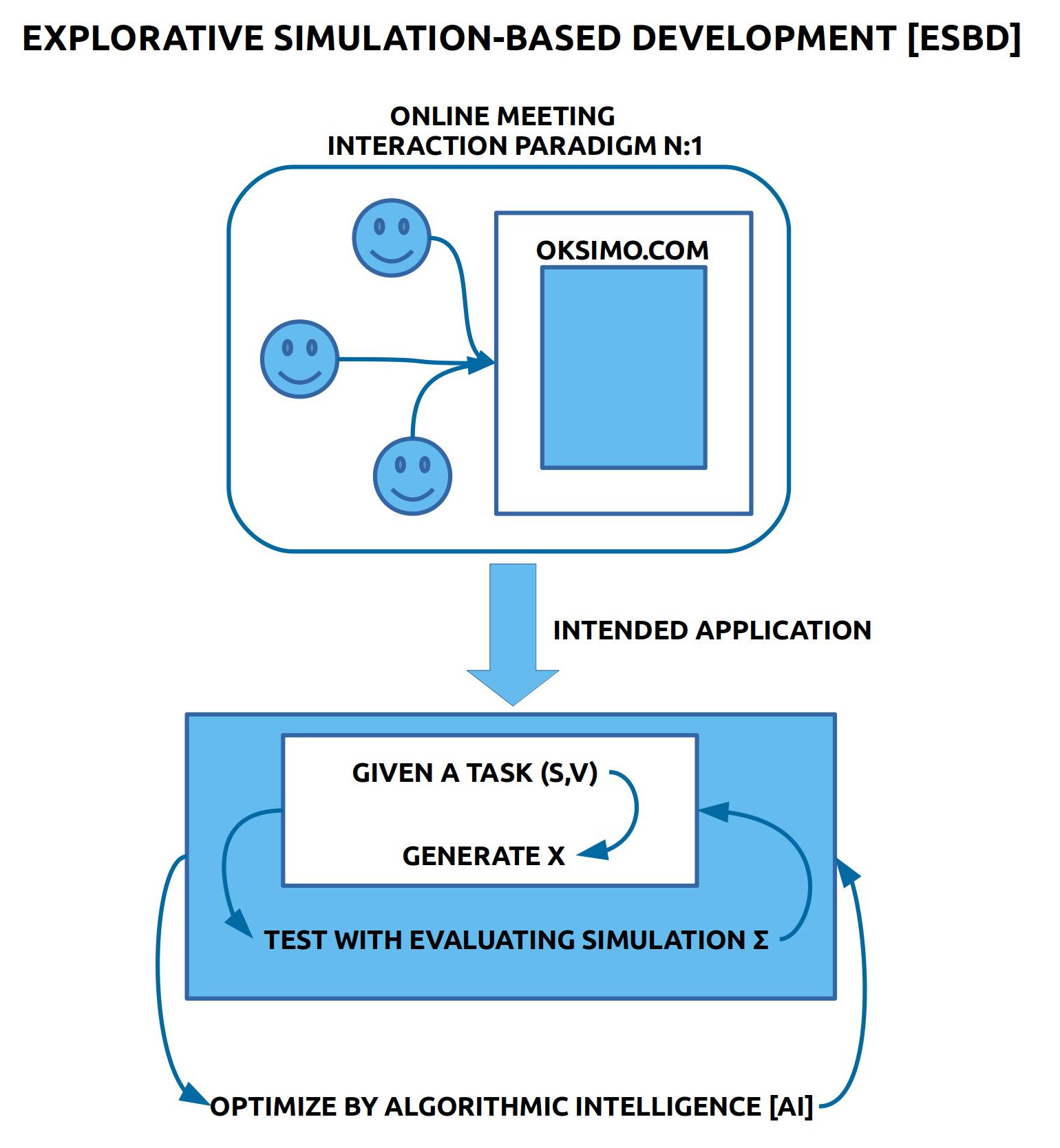
Angenommen es liegt ein Ausgangstext A vor, dazu ein Veränderungstext V sowie eine Anleitung F, dann könnten heutige Algorithmen alle möglichen Simulationen schneller durchrechnen als es Menschen könnten.
Angenommen zusätzlich es läge auch noch ein Zieltext Z vor, dann könnte ein heutiger Algorithmus auch eine Auswertung zum Verhältnis zwischen einer aktuellen Situation als A und dem Zieltext Z berechnen.
Mit anderen Worten: wäre eine empirische oder eine nachhaltig-empirische Theorie mit ihren notwendigen Texten formuliert, dann könnte ein heutiger Algorithmus alle möglichen Simulationen und den Grad der Zielerfüllung automatisch schneller berechnen, als jeder Mensch allein.
Wie steht es aber mit der (i) Ausarbeitung einer Theorie bzw. (ii) mit der vor-rationalen Entscheidung für eine bestimmte empirische oder gar nachhaltig-empirische Theorie ?
Eine klare Antwort auf beide Fragen erscheint mir zum aktuellen Zeitpunkt kaum möglich, verstehen wir Menschen doch noch zu wenig, wie wir selbst im Alltag kollektiv Theorien bilden, auswählen, überprüfen, vergleichen und auch wieder verwerfen.
Meine Arbeitshypothese zum Thema lautet: dass wir sehr wohl lernfähige Maschinen brauchen werden, um in der Zukunft die Aufgabe erfüllen zu können, brauchbare nachhaltig-empirische Theorien für den gemeinsamen Alltag zu entwickeln. Wann dies aber real geschehen wird und in welchem Umfang scheint mir zum jetzigen Zeitpunkt weitgehend unklar.
ANMERKUNGEN
[1] https://zevedi.de/themen/ki-text/
[2] Das Sprechen über ‚Emotionen‘ im Sinne von ‚Faktoren in uns‘, die uns dazu bewegen, aus dem Zustand ‚vor dem Text‘ in den Zustand ‚geschriebener Text‘ überzugehen, der lässt sehr viele Aspekte anklingen. In einem kleinen explorativen Text „STÄNDIGE WIEDERGEBURT – Jetzt. Schweigen hilft nicht …“ ( https://www.cognitiveagent.org/2023/08/28/staendige-wiedergeburt-jetzt-schweigen-hilft-nicht-exploration/ ) hat der Autor versucht, einige dieser Aspekte anzusprechen. Beim Schreiben wird deutlich, dass hier sehr viele ‚individuell subjektive‘ Aspekte eine Rolle spielen, die natürlich nicht ‚isoliert‘ auftreten, sondern immer auch einen Bezug zu konkreten Kontexten aufblitzen lassen, die sich mit dem Thema verknüpfen. Dennoch, es ist nicht der ‚objektive Kontext‘, der die Kernaussage bildet, sondern die ‚individuell subjektive‘ Komponente, die im Vorgang des ‚ins-Wort-Bringens‘ aufscheint. Diese individuell-subjektive Komponenten wird hier versuchsweise als Kriterium für ‚authentische Texte‘ benutzt im Vergleich zu ‚automatisierten Texten‘ wie jene, die von allerlei Bots generiert werden können. Um diesen Unterschied greifbarer zu machen, hat der Autor sich dazu entschieden, mit dem zitierten authentischen Text zugleich auch einen ‚automatisierten Text‘ mit gleicher Themenstellung zu erzeugen. Dazu hat er chatGBT4 von openAI benutzt. Damit beginnt ein philosophisch-literarisches Experiment, um auf diese Weise vielleicht den möglichen Unterschied sichtbarer zu machen. Aus rein theoretischen Gründen ist klar, dass ein von chatGBT4 erzeugter Text im Ursprung niemals ‚authentische Texte‘ erzeugen kann, es sei denn, er benutzt als Vorlage einen authentischen Text, den er abwandeln kann. Dann ist dies aber ein klares ‚fake Dokument‘. Um solch einem Missbrauch vorzubeugen, schreibt der Autor im Rahmen des Experiments den authentischen Text zu erst und beauftragt dann chatGBT4 zur vorgegebenen Themenstellung etwas zu schreiben, ohne dass chatGBT4 den authentischen Text kennt, da er noch nicht über das Internet in die Datenbasis von chatGBT4 Eingang gefunden hat.
DER AUTOR
Einen Überblick über alle Beiträge von Autor cagent nach Titeln findet sich HIER.